
Dive into any large-scale deployment of AI models, and you’ll quickly see the elephant in the room isn’t training cost – it’s inference
Dive into any large-scale deployment of AI models, and you’ll quickly see the elephant in the room isn’t training cost – it’s inference.
Here’s a hard-hitting fact: many AI companies shell out over 80% of their capital just on compute resources. In the words of Sam Altman⁹, Compute costs are eye-watering. Well, welcome to the intriguing & complex world of comparing inference compute costs!
Now imagine you’re an AI start-up or integrating AI into existing systems. As you experiment with APIs from OpenAI and other closed platforms, you’re faced with a dilemma – stick with high-cost, closed-source APIs or switch to customizable open-source models.
Don’t worry, though. We’re here to guide you. In this blog, we’ll simplify the complex world of compute costs in AI, starting with Large Language Models (LLM), helping you navigate this critical decision with clarity and confidence.
Simplifying AI Compute Costs
Imagine a daily user sending 15 AI requests, each request translating to around 2700 input and ~1300 output tokens. Considering Nvidia GPUs for Hugging Face with AWS and Inferless, we found it takes about 1.3 seconds to serve a request.
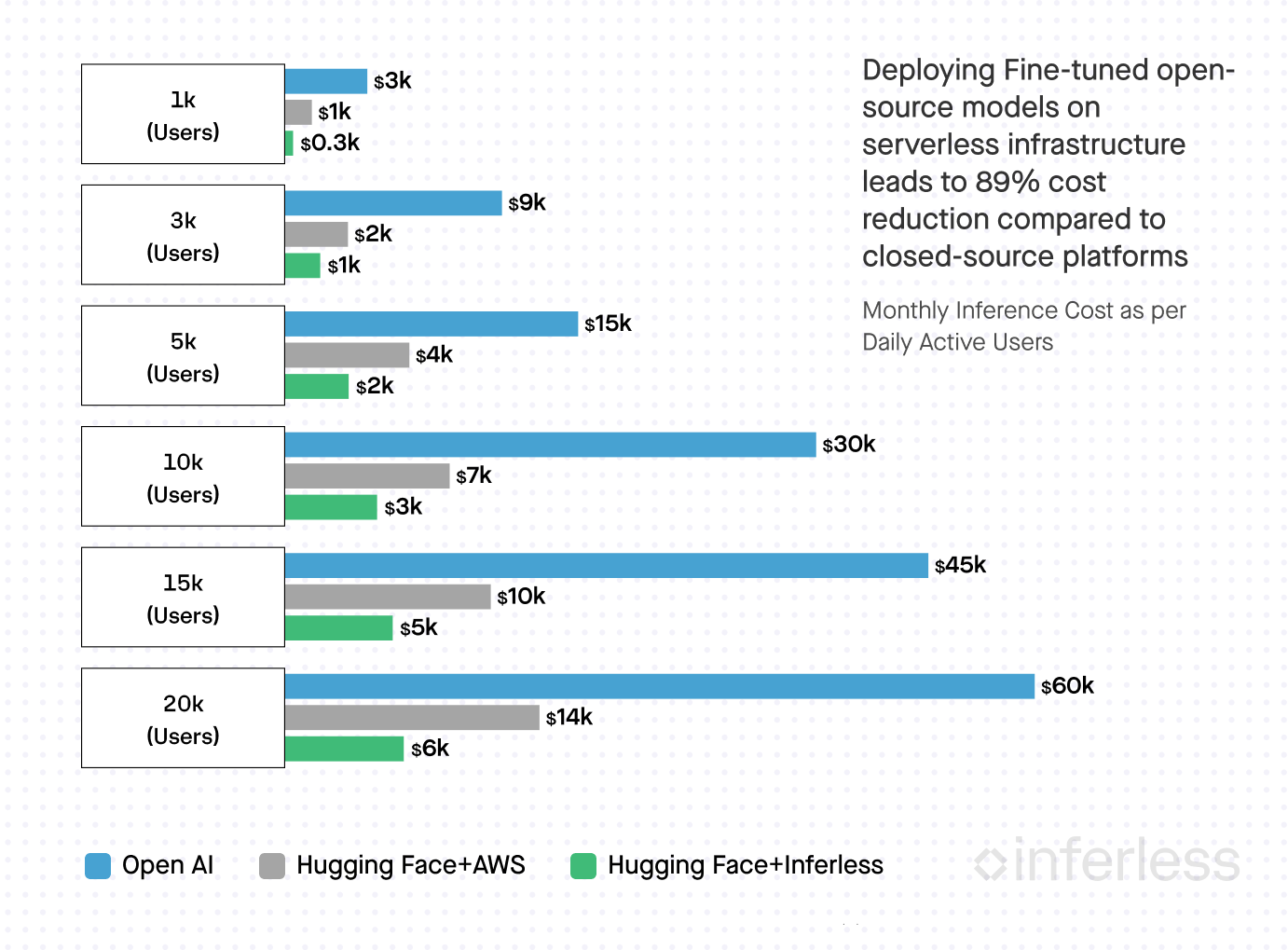
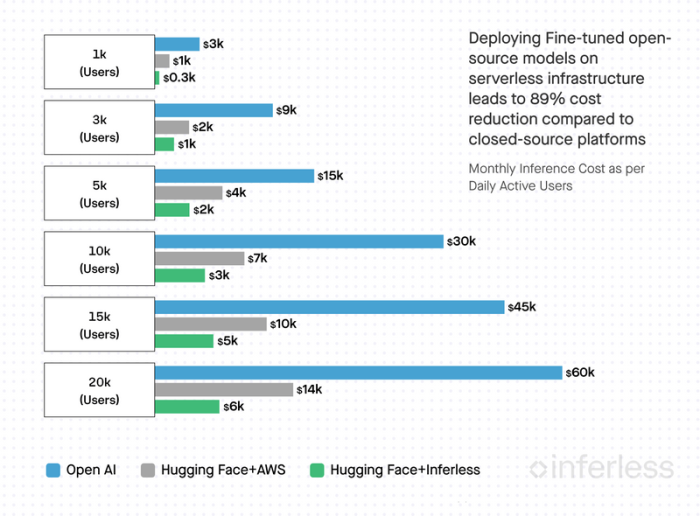
Our exploration shows that Hugging Face + Inferless costs 89% less than OpenAI and 55% less than Hugging Face + AWS. Meanwhile, Hugging Face + AWS costs around 77% less than OpenAI.
We’ve drilled down into these numbers in the following sections. We welcome any challenges to our assumptions. We’re quite certain we’re on the right track, but we’re open to adjusting these estimates for better accuracy.
Let’s explore the pros, and cons⁷, and compute costs of each of these methods in more detail.
Three Pathways to Generative AI Enterprise
[Image unavailable: HTTP 403]
Option 1: Leverage Pre-Built APIs
The world of tech brims with ready-made machine learning models from industry leaders. Kick-starting AI applications using these pre-existing models and APIs is a quick and convenient strategy. However, remember, as your product scales, so do the costs.
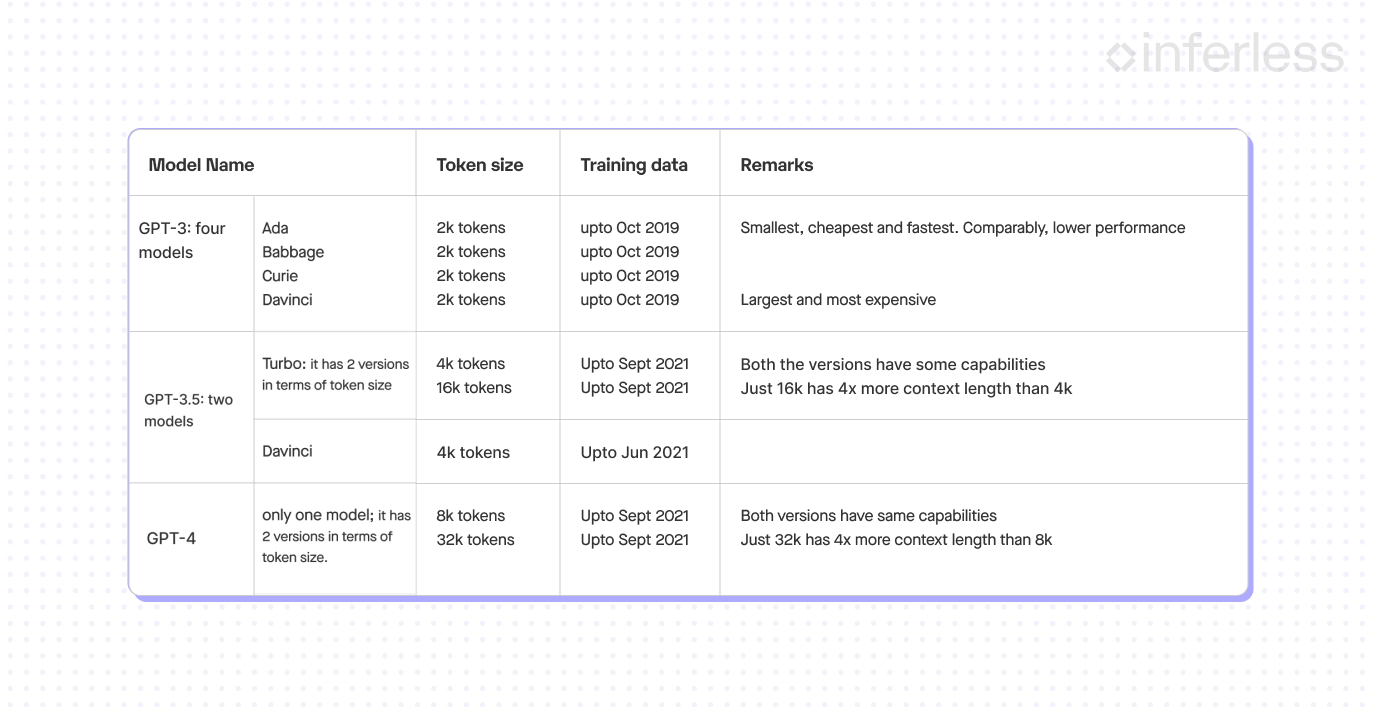
A Peek into OpenAI’s GPT Catalog
OpenAI presents an array of GPT-3 models like Ada, Babbage, Curie, and Davinci. From the economical Ada to the high-performing, premium-priced Davinci, there’s a model for various needs. The best fit will require some trial and error.
Subsequent GPT-3.5 and GPT-4 releases offer models with differing context length capabilities. Remember, similar features don’t equate to similar performance in varying contexts.
Here’s a handy chart to navigate OpenAI’s offerings⁸. Save it for your future reference.
Option 2: Fine-Tune Open Source Models
Open-source platforms like Hugging Face Hub, PyTorch Hub, TensorFlow Hub, and ONNX Model Zoo are fueling the AI revolution. Of these, Hugging Face shines brightest, hosting 120k+ models and 20k datasets, as well as offering 50k demo apps¹.
You can take a pre-trained model from Hugging Face Hub and adapt it to a new task or domain by training it on new data. This process is called fine-tuning. The advantage of fine-tuning is that you are able to get to a high level of precision for your specific use case without having to train the model from scratch.
Hugging Face is an all-in-one platform for AI development, collaboration, and scalability. Continue reading to learn about integrating these models and the associated costs.
[Image unavailable: HTTP 403]
Option 3: Training a Model from Scratch
Sometimes, using a pre-trained model isn’t enough, especially with highly unique data. In such cases, a custom-built model, trained on specific data like legal documents, can provide an unmatched level of precision² and become an invaluable resource for professionals.
Despite its benefits, training a model from scratch is resource-intensive. Once trained using platforms like Hugging Face, deployment and inference follow similar steps to Option 2. Although building a custom model allows more flexibility, it also incurs more costs and resources. It’s important to consider these factors before choosing this route.
Navigating Inference Costs: A Detailed Overview
As your application scales, understanding inference costs can guide you toward cost-efficient solutions. To help you visualize this, we’ve analyzed the costs of inference as an application scales from 1k daily active users (DAUs) to 20k DAUs.
[Image unavailable: HTTP 403]
Our Key Assumptions
To arrive at these conclusions, we made several important assumptions:
1. Daily Active Users (DAUs): We assumed each user sends an average of 15 requests per day.
2. Request Composition: Each request corresponds to a medium conversation with four input-output pairs. The total input tokens amount to approximately 2,700, and the total output tokens are around 1,300. Here’s a visual representation of how we counted the tokens³:
[Image unavailable: HTTP 403]
3. Model Assumptions:
– For Open API: GPT-3.5 Turbo API with a 4K context length. – For Hugging Face to be deployed on AWS & Inferless: a fine-tuned DialoGPT-large model on your data.
4. Pricing Models: We then took into consideration the pricing models of various services:
– For OpenAI, we used the pricing for the GPT-3.5 Turbo API with 4K context length, which is $0.0015 per 1,000 input tokens and $0.002 per 1,000 output tokens⁴. – For Hugging Face’s DialoGPT-large With AWS, we considered the cost of using an On-demand Nvidia A10G GPU g5.xlarge, priced at $1.01/hour.⁵ With Inferless, we factored in the cost of a Nvidia A10 GPU, priced at $0.000555/second.⁶
5. Service Time: Based on our tests, we found that it takes around 1.3 seconds to serve a single request across these platforms.
By combining these assumptions, we were able to calculate the estimated costs you can expect as your application scales.
Breaking Down the Costs for Each Provider:
OpenAI
How we calculated Inference Cost Per Query:
OpenAI charges $0.00665 per query, which is calculated based on 2700 input tokens and 1300 output tokens. Here 1,000 tokens is about 750 words. The cost per 1000 input tokens is $0.0015 and the cost per 1000 output tokens is $0.002⁴. Hence cost per query comes to $0.00665 (computed as 2700*$0.0015/1000 + 1300*$0.002/1000)
Hugging Face + AWS EC2 (g5.xlarge):
How did we determine Average GPU Replicas?
Step 1: Calculate Average Number of Queries
Consider scenario of 10k DAUs, each sending 15 queries daily, we can calculate the average number of queries per hour. It comes to 6.3k (calculated as 10k DAUs * 15 queries/user divided by 24 hours/day).
Step 2: Determine Queries per Second (QPS)
80% of these queries (i.e., 5k queries) will arrive within 20% of a 60 minute window (12 minutes). Our infrastructure must be able to handle these 5k queries within this period. This amounts to roughly 7 QPS (5000 queries divided by 720 seconds).
Step 3: Set Average Replica Count
Given that an Nvidia A10G can handle 1 query in 1.3 seconds (0.77 QPS), we need to set an average of 10 replicas to manage the load (7 divided by 0.77).
Note that if your load is highly variable with no clear pattern, you may need to set a higher average replica count. On the other hand, if you’re looking to save costs, you can set a lower replica count and rely on autoscaling during spikes. However, be aware that this may affect user experience.
Hugging Face + Inferless (Serverless GPU)
How we calculated Inference Seconds
Let’s continue with the scenario of 10k DAUs each sending 15 queries daily. Over a month, that equates to 4.5 million queries (calculated as 10k users * 15 queries/day * 30 days/month). As it takes 1.3 seconds to process one inference request, you will need approximately 5.85 million inference seconds per month (calculated as 4.5 million queries * 1.3 seconds/query).
Note that with this method, you only pay for your usage and nothing more. You are charged only for inference seconds used and save on charges you were paying for idle capacity in the HF + AWS method.
In Summary
OpenAI and other closed-source companies have played a significant role in advancing generative AI. However, the open-source community has made impressive progress too. There are now many high-quality open-source platforms that offer cost-effective alternatives, often outperforming closed-source options.
Smaller, domain-specific models are now preferred by many businesses over larger, general-purpose models like GPT-3.5. These custom models offer greater control, privacy, and cost-efficiency.
To make informed decisions about AI, particularly Large Language Models, it’s important to understand the related compute costs. This can be overwhelming, but with the right guidance, you can confidently navigate this process. Stay updated and informed to leverage the benefits of AI effectively.
Just a gentle reminder: We appreciate and look forward to your thoughts or insights to help refine our computations and enhance accuracy. Our objective is to empower decisions with data, not to discount any provider. For those interested in exploring Inferless further, feel free to join our waitlist here.



.png)