

Techniques to make LLMs proficient in math and symbolic reasoning – by a former ML Engineer Photo generate by DALL-E 3 with prompt ‘AI that can reason and looks like a mathematician’ In a latest news by Reuters, several OpenAI staff researchers wrote a letter to the board of directors warning them of a powerful AI discovery (potential AGI) from an internal project named Q-Star that they said could threaten humanity
Techniques to make LLMs proficient in math and symbolic reasoning – by a former ML Engineer

In a latest news by Reuters, several OpenAI staff researchers wrote a letter to the board of directors warning them of a powerful AI discovery (potential AGI) from an internal project named Q-Star that they said could threaten humanity. The letter claims that the AI can already solve grade-school level math problems better than humans. But how can math proficiency lead to AGI? A machine that can perform mathematics beyond rote memorization should, in theory, be able to learn to do other tasks that build on existing information, such as writing computer code or drawing conclusions from a news article, remarkably well. Currently, GPTs are poor at successfully breaking down math problems, especially the complex ones. But haven’t we all used chatGPT for calculating those IRRs and ROIs for our study and work assignments? It sometimes does the job because GPTs have memorised the formulae (ROI = Profits / Cost) from the petabytes of data they are pre-trained on! As a former Machine Learning Engineer who has built e-commerce customer support bots, I have tried hard, often unsuccessfully, to make chatbots better at answering queries that require mathematical and commonsense reasoning. This blog is an attempt to combine my past experience with the cutting-edge research by research labs at OpenAI, Deepmind, and Microsoft. If you are trying to make your LLMs more skilled at reasoning or are simply curious about the next paradigm shift in LLMs, keep reading! In this article, I propose an LLM architecture including data processing, prompting, and Reinforcement Learning techniques to create a customer support bot that is capable of answering customer queries that require mathematical, commonsense, and symbolic reasoning. A typical chatbot receives thousands of these daily. Let’s see some examples-
How much would I save annually if I switch to an annual Prime membership from a monthly one? What can I expect my refund and how much will it be? I need 150 units of a product for a bulk order. Is there a discount, and what is the total cost?
RLHF — Its all in the basics !
Reinforcement Learning with Human Feedback (RLHF) is one of the fundamental processes that enables LLMs to reason the world around them. Let’s visualize how RLHF works — say, we want to train a chatbot capable of human like reasoning and conversation. The system visualized as an RL model would look something like below-
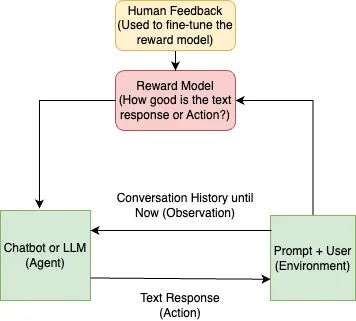
While we can spend hours on the science behind RLHF, we will focus on how it lends LLMs the ability to reason. The trick is in the Reward Model (or RM) that helps score each response by the chatbot indicating how ‘aligned’ the output is with the expected behaviour coded through manual labeling of the dataset. These scores lie between 0 to 1 with 1 indicating the perfect human-like response. Train the system long enough with RM’s feedback and chatbot’s responses will start mimicking that of humans. To build reasoning capabilities, train the model on data that contains logical deduction and reasoning-based situations including CommonsenseQA, strategyQA, SQuAD (Stanford Question Answering Dataset), and Quora Questions Pairs. OpenAI’s InstructGPT introduced the effectiveness of this methodology to the world. Lets see some examples of training prompts and their desired output responses ( written by an annotator for training)-
Q: Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis balls does he have now? (Math Word Problems)
A: Roger has 11 tennis balls.
Q: Yes or no: Would a pear sink in water? (Strategy / Common Sense)
A: No
Q: Take the last letters of the words in “Lady Gaga” and concatenate them. (Symbolic reasoning)
A: Lady Gaga → y and a → “ya”
But just training on reasoning based Q&As is not enough. Next we will modify this architecture to build an LLM pipeline that is capable of human-level reasoning on math and commonsense / strategy related questions. These techniques by leading AI research labs including Deepmind, OpenAI, and Microsoft has proven to take the problem solving accuracy on GSM8K (Grade School Math dataset) from 18% to 80%+ since 2021!
[Image unavailable: too large: 5.2MB]
Prompt Processing and Augmentation
As with any ML pipeline, lets start with data processing — converting natural language into mathematical equations often results in better accuracy on reasoning tasks. LLMs tend to understand mathematical equations and formulae better than the natural language. Additionally, augmenting the prompt with additional information about the agent states (eg. customer and product data) about through Retrieval Augmented Generation (RAG) can lead to more accurate responses. Lets see how the data processing workflow would look for the reimbursement limit query discussed earlier-

Prompt with reason — Chain of Thoughts (CoT)
Consider your own thought process when solving a complicated reasoning task such as a multi-step math word problem. It is typical to decompose the problem into intermediate steps and solve each before giving the final answer: “After Jane gives 2 flowers to her mom she has 10 . . . then after she gives 3 to her dad she will have 7 . . . so the answer is 7.” Sounds like a chain of thought? Turns out if you provide a few shot examples of such chain of thoughts while prompting, the LLM responses on math and reasoning tasks become more accurate. This technique, also called Chain of Thoughts (CoT) prompting, is one of the most successful techniques in making LLMs better at reasoning. But how many examples does a prompt need and how should they look like? Somewhere around 8 seems to be the magic number. The official CoT paper by Google brain provides different set of 8 examples of each reasoning task i.e Math Word Problems, commonsense (Strategy), and Symbolic reasoning questions that you can pick from. You also don’t have to stick to these examples — turns out if you create your own examples in the format <Input, Chain of Thoughts (COTs), Output> or provide fewer examples (say somewhere between 4–8), LLMs still produce comparable responses. For my customer support chatbot project, I had to gather a team of annotators to create a repository of 1500 examples of CoT responses for customer support queries including reimbursement limit and ROI of an annual membership. Applying COT prompting has shown a significant improvement on GSM8K dataset — 17.9% to 58.1% in problem-solving rate ! Lets see how a CoT might look like for an input prompt- –

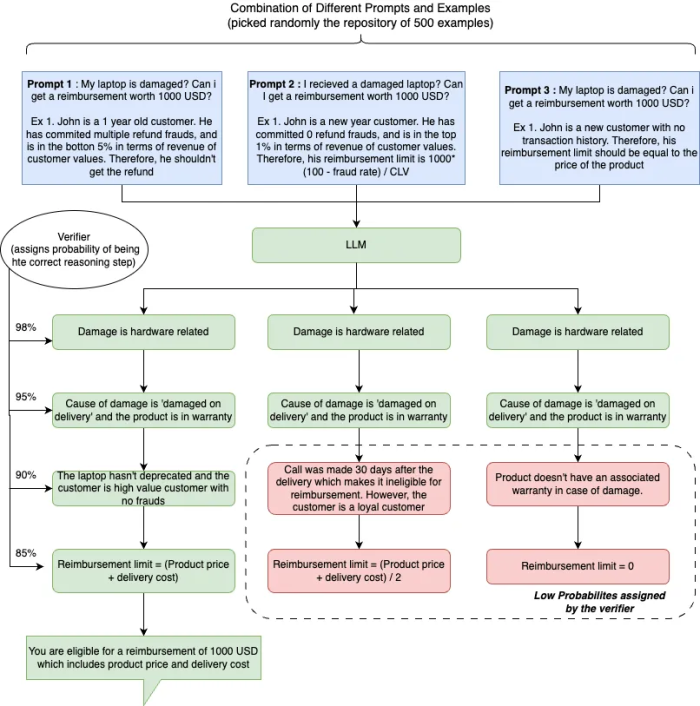
One reason ain’t enough — Diverse Verifier on Reasoning Steps (DIVERSE)
Chain of Thoughts (CoT) has its limitations. Let’s revisit the prompt in the CoT illustration— ‘I received a damaged laptop. What’s my reimbursement limit?’ In answering this, did you think of just line of reasoning? Not really ! There are many ways to get to the solution— “The customer is loyal so we should reimburse the entire cost” or “The product is not in the warranty period and the customer reached out much after the delivery date so we can only reimburse half the price” and so many more… So why should LLM explore just one chain of thought as prescribed by the CoT prompting? Like our own thought process, its better to explore multiple reasoning paths and then finalize the one that’s most reasonable. DIVERSE (Diverse Verifier on Reasoning Steps) method by Microsoft does that — it explores multiple chain of thoughts (~50 ) and selects the one that is most likely to lead to the correct answer. The multiple chains are created by sampling randomly from a pool of examples or from the decoder’s output. Each reasoning path is assigned a likelihood of leading to an accurate answer through a verifier, an LLM. Moreover, the verifier is step-aware i.e it analyzes the likelihood of every reasoning step. But why step awareness? It helps diagnose and rectify situations where a correct answer is obtained through a flawed reasoning, improving the overall reasoning proess. Authors of DIVERSE demonstrated that supplementing Chain of Thoughts (CoTs) with above modifications increases the problem solving rate on GSM8K dataset from 60% to 85%+ . Lets fall back to our reimbursement limit example to understand how DIVERSE can be applied to it successfully-
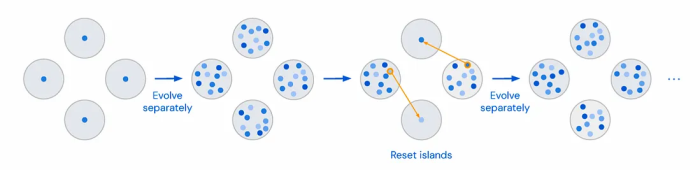
More the Merrier — Funsearch by Deepmind
While DIVERSE has allowed us to achieve 85%+ accuracy on math-related problem sets, it is really hard to implement in production. First, the prompts used in the algorithm are not diverse enough to create distinct reasoning paths. All it does is use a different set of examples from a repository but the core prompt remains the same. Can we somehow use the existing 1500 Q&A examples to build a large library of exemplars that are diverse and of higher quality? A recent paper by Deepmind ‘FunSearch: Making new discoveries in mathematical sciences using Large Language Models’ gives us some clues. It utilizes a parallel genetic algorithm called the islands model to create a diverse set of computer programs using an initial set of programs to solve a previously unsolved combinatorial problem. Sounds relevant right? The approach is simple — we split the population of Q&A examples (GSM8K dataset) into m separate groups, or islands. Each island is initialized with a copy of the examples and is evolved separately. What’s evolution you ask? A random set of k-examples is chosen from each island and passed through an LLM to create a new set of prompts (aka evolution). These new prompts are evaluated using a Reward Model and the best ones are stored on the island. To ensure that lower quality (or score) examples are removed from the search, we discard all the examples from the m/2 islands whose best instances have the lowest score. Each of these islands is then seeded with a single prompt from the remaining island and the process repeats until 5000+ prompts above a threshold quality score are created. Separate evolution between the islands ensures diversity in the prompts and the elimination of lower-score islands ensures quality.
Finishing Touches — Process Reward Models (PRM)
Now that we can create diverse prompts, the other big limitation is the verifier. Verifier, being an LLM, is data hungry requiring a lot of training examples (~10k) for fine-tuning, making it costly. Moreover, verifier outputs suffer from hallucinations which in a sequential reasoning model like CoT can increase the downstream risk of incorrect answers. To overcome these limitations, the verifier can be replaced by RL based Process-based Reward Models (PRMs) as proposed by OpenAI in their paper ‘Lets Verify Step by Step’. But how will it work? And how will it overcome the existing limitations of LLM based verifier?
PRMs, like the verifier in DIVERSE, evaluate each reasoning step for its relevance to determine the correct answer. However, unlike verifier, PRMs can be trained via traditional RL algorithms, which reduces its data requirements significantly. Moreover, an active learning approach suggested by OpenAI reduces the data labeling requirements by 2.6x. Not all data points need to be labeled — initial labeling of each data point should be done by a pre-trained LLM (like GPT-4) and manual labeling should only be done for datapoints that are ‘convincing wrong answers’ i.e solutions that have correct answers but incorrect reasoning. This would allow the labeling bandwidth to be allocated to tricky datapoints that confused the previous iteration of the PRM. In the next iteration, the PRMs are re-trained on the on these new data points that are manually labelled for better performance.
Phew! That was a lot but we have finally reached an architecture that offers an accuracy of 85%+ on mathematical reasoning tasks and can be deployed in production at a reasonable cost. Let’s see how this final LLM architecture would look-
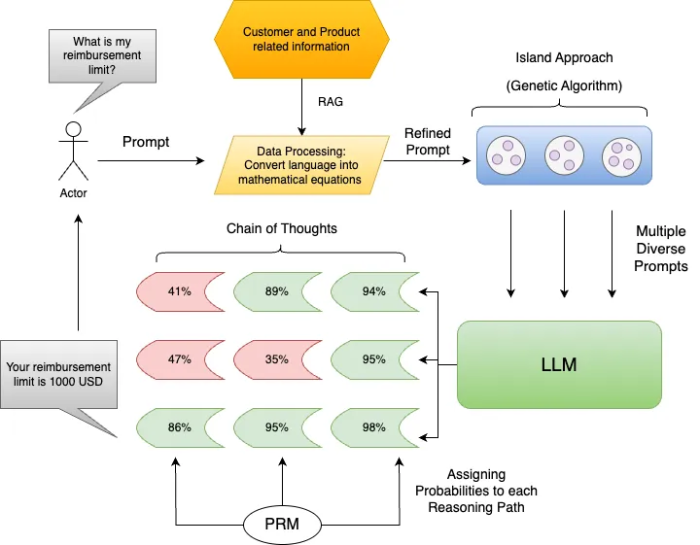
Conclusion
In the last 2 years, we have come a long way to the point where LLMs, like humans, can explain their chain of thoughts behind an answer, can explore multiple reasoning paths, and take the one that has the most likelihood of leading to the correct answer. However, I believe we are still a long way from an AGI. Researchers are trying to improve the accuracies of these reasoning paths further — one prominent area of research is the ‘Tree of Thoughts’ approach which allows for these distinct reasoning paths to intersect with each other. In this case, the exploration for an optimal reasoning path then takes a form of a walk along these paths using Depth-first (DFS) or a breadth-first (BFS) search methods. I will link a few readings below if you are interested to explore those ideas further.
The next part of this blog will include a code base to implement all the ideas suggested in the blog. So stay tuned! If you have any questions, suggestions, or ideas you are currently exploring in the LLM reasoning space, I would love to talk. You can reachout to me on LinkedIn or my email.
Additional Readings-
- Reasoning with Language Model Prompting: A Survey.
ACL 2023Shuofei Qiao, Yixin Ou, Ningyu Zhang, Xiang Chen, Yunzhi Yao, Shumin Deng, Chuanqi Tan, Fei Huang, Huajun Chen. [Paper] [Code], 2022.12 - On Second Thought, Let’s Not Think Step by Step! Bias and Toxicity in Zero-Shot Reasoning.
ACL 2023Omar Shaikh, Hongxin Zhang, William Held, Michael Bernstein, Diyi Yang. [Paper], 2022.12 - Self-consistency improves chain of thought reasoning in language models.
ICLR 2023Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, Denny Zhou. [Paper], 2022.3 - Ask Me Anything: A simple strategy for prompting language models.
ICLR 2023Simran Arora, Avanika Narayan, Mayee F. Chen, Laurel Orr, Neel Guha, Kush Bhatia, Ines Chami, Frederic Sala, Christopher Ré. [Paper] [Code], 2022.10 - Tree of Thoughts: Deliberate Problem Solving with Large Language Models
PreprintShunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, Karthik Narasimhan. [Paper] [Code], 2023.5
Benchmark
Some Benchmarks for quantifying the reasoning abilities
- Reasoning AbilityBenchmarksArithmetic — GSM8K / SVAMP / ASDiv / AQuA / MAWPS / AddSub / MultiArith / SingleEq / SingleOp / Lila
- Commonsense — CommonsenseQA / StrategyQA / ARC / BoolQ / HotpotQA / OpenBookQA / PIQA
- Symbolic — CoinFlip / LastLetterConcatenation / ReverseListLogicalReClor / LogiQA / ProofWriter / FLD / FOLIO
- Other — ARB / BIG-bench / AGIEval / ALERT / CONDAQA / SCAN / WikiWhy


