
Virgin Media O2 is transforming into a digital-first company — putting data at the heart of what we do and delivering a best-in-class digital experience to our customers
Virgin Media O2 is transforming into a digital-first company — putting data at the heart of what we do and delivering a best-in-class digital experience to our customers. Machine Learning (ML) is foundational to this transformation, as it enables customer journey personalisation, network fault prevention, product recommendations and more.
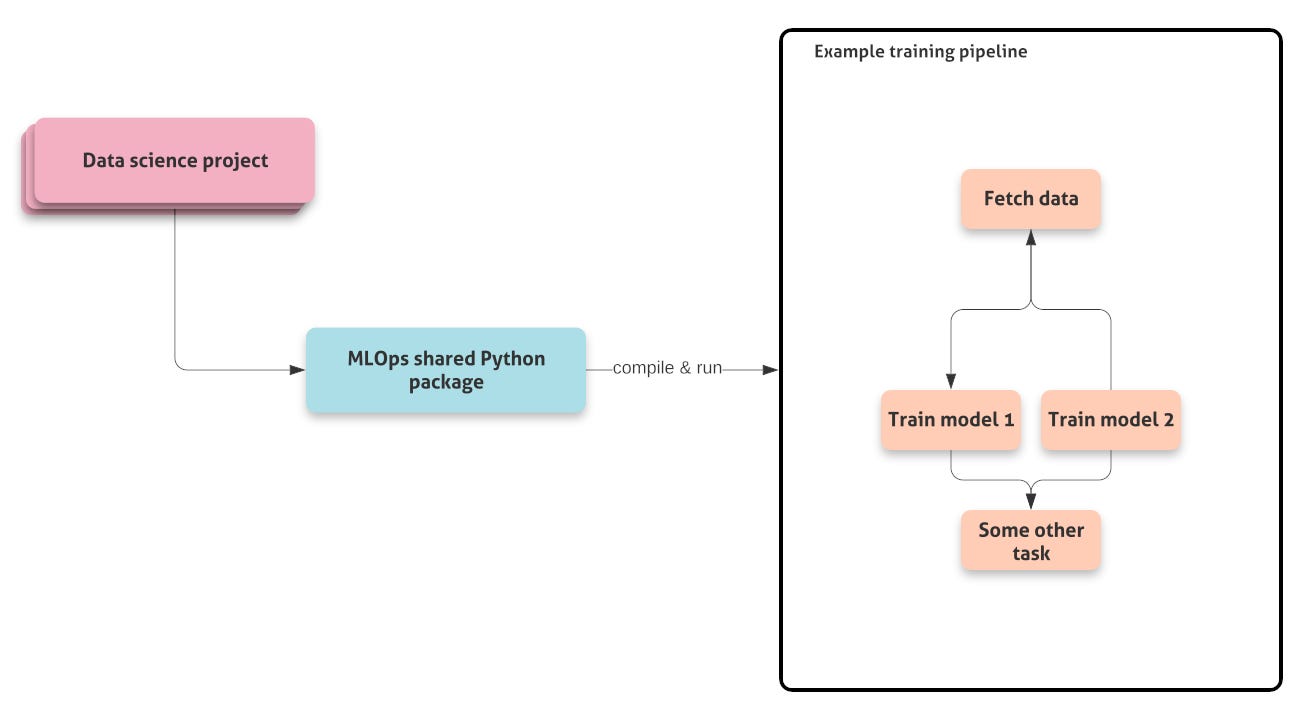
The MLOps Platform at VMO2 allows our data scientists and analysts to explore the data, iterate on ML-based solutions and productionise these solutions to make a real impact to enhance the digital experience for our customers.
At the heart of this tooling sits Vertex AI Pipelines, which is Google Cloud Platform’s service that uses Kubeflow Pipelines (KFP) under the hood for creating end-to-end machine learning pipelines. Our platform’s design and adoption are described in our previous blog post.
In this article, we share how we solved the problem of managing multiple container environments to allow for leaner and faster pipelines, enabling us to scale the number of productionised ML products further.
On the MLOps Platform, each pipeline is made up of a series of Vertex AI Pipelines components, and each component consists of two parts:
1. Python code containing the component logic, which may require any number of third-party libraries and external services like BigQuery, GCS, etc. to fulfil its objective
2. A container environment for this component code to run in, that contains all the necessary dependencies
We provide and maintain both in order to supply the users of our platform with entirely reusable pipelines with a neat interface, so that they are only required to pass a few config values that are unique to their project.
For shared code, we have an MLOps Python package that contains the Vertex AI Pipelines components, helpers and CI/CD utilities.
This has enabled data scientists to rapidly prototype and deploy their ML pipelines, and the number of machine learning models that are deployed to production has seen rapid growth, going from four models to 25 in a matter of seven months.
A hundred eggs, one basket
In the past, for the container environment, we maintained an image containing all the dependencies that users might need in their pipelines. Every task in every pipeline used the same container, and any packages that a new project may have needed that wasn’t already on the container, could be added with a pull request to our container repository which would then build and push the new version of this container.
We also used to install the shared MLOps package into a container for shared utilities and kept the container tag synced with the package version, which is important for locally-triggered pipelines. The package was also used as the source of truth for dependencies on KFP and Dataflow containers.
This approach, however, grew increasingly less successful and more prone to issues as the number of data scientists and projects grew over time.
It did come with some benefits:
· All the tasks used the same version of a particular package, as they are using the same environment. This meant that we didn’t face incompatibilities when reading the output of a task from a downstream task, for example.
· To see what those packages and versions are, we simply had to look at the poetry.lock file for that one environment image.
· We could use the container caching capability of Vertex AI Pipelines to fetch the container image once at the start of the pipeline, and then run the remaining tasks on the cached container for a faster task start-up time.
· It was easier for stakeholders to know where to go to add packages that they wanted, because there was only one environment image.
However, there were also some major downsides:
· Upgrading a package version in the environment can be difficult because other users may not be ready to upgrade or have tested compatibility, so existing projects miss out on new features, and new projects are held back.
· Adding new packages to the container also becomes increasingly harder and slower due to dependency conflicts.
· The container image would be huge, and continually growing as users would add new packages, slowing down node start-up times and increasing costs for downloading from across regions.
· Because our MLOps package is used both locally to trigger pipelines, and on the container in Vertex for execution, and is used as the source of truth for our dependencies, people interacting with our platform end up installing all these dependencies into their local virtual environment, which can be painfully slow on a slow internet connection.

Separating the yolk from the white
We wanted to address these problems before things got out of hand, and we also wanted to reduce the number of support tickets that came our way, because who wants a pile of support tickets?
KFP emphasises the separation between the code containing the logic and the container environment in which it runs that contains all the necessary dependencies, as described earlier in this article. One way of doing this is to decorate your Python function with the @component decorator (passing in the base/target image arguments) and let KFP turn it into a component.
The other option is to build your own images that contain all runtime dependencies and instruct components to use them. This approach ensures that job runtimes are scanned and free of security exploits, allowing us to restrict runtime access to the internet and allowing use of deterministic package installs via poetry instead of crossing our fingers with pip.
This presents a mindset change where the container image should be targeted to specific components and only contain the necessary dependencies to execute that piece of code, and certainly shouldn’t include the code of the component itself. In other words, the componentlogic should be decoupled from the environment in which it runs, allowing the code to run in multiple environments, and environment reuse for multiple components (see Figure 3 below).

This brings several benefits:
· The most obvious one is that images can be much more lightweight. If you are pulling some data from BigQuery in a task, there’s no need to include large packages like TensorFlow just because they might be used later in the pipeline for another task.
· Issues regarding start-up time disappear, because your image may be anywhere from 1/2 to 1/50 of the size depending on how self-contained your component logic is and how large its dependencies are.
· It simplifies development, as component code is copied into the container at runtime, allowing for testing using the existing image in production for that task.
· We can also now likely add or upgrade packages much more easily, because the number of potential dependency conflicts is dramatically reduced by having very few packages per image.
· Supporting multiple versions of packages like Tensorflow or CatBoost can be done by creating multiple images with specific versions. Bonus points for setting up a testing rig that runs and tests across containers with multiple package versions when core functionality changes.
· On the subject of testing, we can now create simple integration tests that run our component code inside an environment (or many of them), whereas previously we would have had to install our package onto our container after every change in order to run the tests.
We addressed all the problems in our previous approach — great! As with everything though, there are some potential downsides to consider, as more containers means more complexity and more things to maintain:
· Images will have dependencies in the form of pyproject.toml and poetry.lock files, but many dependencies overlap and kfp is duplicated across many images. It’s easier to update a package version within a specific environment, but important to have a good end-to-end testing strategy to avoid breaking the pipeline.
· It might be more difficult — for users less savvy with your set-up — to know where to go to add or update a package, especially if that means having to create a new environment altogether.
A simple but efficient way we mitigated the first point was to look at our components and examine if there were any that required the same or similar dependencies, or some that made sense to group semantically, and create an environment image that serves these multiple components. For instance, you might have a component that pulls data from BigQuery, and another one that interacts with Google Cloud Storage. It would then make sense to create an environment image that includes both libraries to interact with these services, as they are both Google Cloud libraries and share many of the underlying dependencies.
The second issue was solved with good documentation and an efficient template for creating a new container environment. With that, anyone can follow simple instructions to create and use a new container in their pipeline.
The Lay of the Land
To give you an example of some of the environments we created for our pipelines, we can have a look at the way we’ve set our model environment containers up.
We supply a basic model training task in our package that data scientists can use if they don’t want to write any custom logic, and we support a range of libraries such as XGBoost, CatBoost, scikit-learn and TensorFlow. In our new world of separate environments, we not only want to have separate images for each one, but we also want to be able to support multiple versions of these packages as different projects may have different requirements depending on when they were initiated.
All we need to do to achieve this is a pyproject.toml and a poetry.lock file for each environment we want to build, and we can get our CI/CD to only build our images when the poetry.lock changes for a particular image. Furthermore, we can now test our model training component across multiple packages and multiple versions of each package because we’ve modularised everything and they can fit together in multiple combinations at runtime.

The final piece of the puzzle is dealing with the helper code in our package that was previously installed into our single container environment and was available from every task in our pipeline.
We wanted to separate our logic from our environment, and while KFP helps us get our component code onto the container, it doesn’t help with any other functions in our codebase that we might be importing and calling within our component code. This means that we want to get our helper code onto the environment at runtime, just like KFP is doing under the hood.
We wrote a function that wraps the KFP component creation, that we call to create the component at compile-time, and that we can pass a series of module paths to, denoting the helper modules that component requires in its execution. The function will then hook into the command that is to be run on container startup (that KFP uses to run our component code), make it write out the code for the modules we’ve specified as dependencies into the corresponding path on the container, and place those files onto the PYTHONPATH. This means that any imports that happen in the component code stay the same regardless of whether the code is being executed locally or on the container. And we don’t have to burn any code onto the environment container.
While this works as intended, and we have tested the functionality extensively, we expect to move to the KFP v2 way of doing it once it is released — taking an environment container as our base image, packaging up all the necessary code and then using the kfp CLI to build and push a target container for execution.
Conclusion
The growing number of users on our platform exposed some issues of our Kubeflow Pipelines setup, but adopting the mindset of creating “dumb” environment containers for KFP components to run in has allowed us to create lean and reusable images that are much easier to maintain, update, and add to, while also making our development flow much easier by removing the need to build dev and staging containers in order to test new code. We are also in a much better position to upgrade to v2 of the KFP SDK, as we are more aligned with the philosophy and best practices of the tool.
For our users, we’ve seen some benefits in the form of a super lean MLOps package on their local machines that is quick and easy to install, going from upwards of 2GB down to 147MB, which reduces friction in terms of upgrading or starting a new project. Our pipelines have also seen an average decrease in running time of ~11% despite not being able to cache a single container throughout the pipeline, because it’s much quicker to download and initialise the lean, isolated environments.
All of this has put us in a position to scale our platform effectively for future growth while also making it easier for our users to interact with and build on top of our platform. As a result of this work, we can now onboard even more ML products that will help Virgin Media O2 to create best-in-class digital experience for our customers.
By Berk Mollamustafaoğlu, Senior MLOps Engineer at Virgin Media O2
On behalf of the VMO2 MLOps team: Alex Jones, Ariyo Oluwasanmi, Gleb Lukicov and Sidney Radcliffe.
By the way, the team at Virgin Moble is hiring! Want to work for them? Check out our open roles here.



.png)