This article ( original post ) is written by Ernest Chan When you only have one or two models to deploy, you can simply put your models in a serving framework and deploy your models on a couple of instances/containers
This article ( original post ) is written by Ernest Chan
When you only have one or two models to deploy, you can simply put your models in a serving framework and deploy your models on a couple of instances/containers. However, if your ML use cases grow or you build separate models on many segments of your data (like per-customer models), you may eventually need to serve a large number of models. This post will explore the question: How do you design a system that can serve hundreds or even thousands of models in real-time?
First, what changes when you need to deploy hundreds to thousands of online models? The TLDR: much more automation and standardization. Usually, this means an investment in a model serving platform.
Companies like Reddit, DoorDash, Grab and Salesforce have built model serving platforms to:
- Meet their scale requirements, both of the number of models and requests per second.
- Make it easier for ML teams across the organization to deploy models.
- Provide capabilities like shadow mode, gradual rollouts, and monitoring.
- Ensure consistent SLAs for model serving, which may involve implementing optimizations that benefit all models on the platform.
Although each organization built its system independently, the high-level designs are surprisingly similar. Below is my synthesis of a general design.
This post will mainly focus on the model serving architecture for serving a large number of models and will not cover other aspects like model CI/CD or compare serving frameworks.
The Developer Experience
Let’s start with how a Data Scientist/ML Engineer deploys a new model on the platform. They
- Save the trained model to a model store/registry.
- Provide a model config file with the model’s input features, the model location, what it needs to run (like a reference to a Docker image), CPU & memory requests, and other relevant information.
Basically — here’s my model artifact and here’s how to use it. The two steps may be streamlined by an in-house tool. Deploying a new model may even be automated in the case of automated retraining.

Serving Architecture
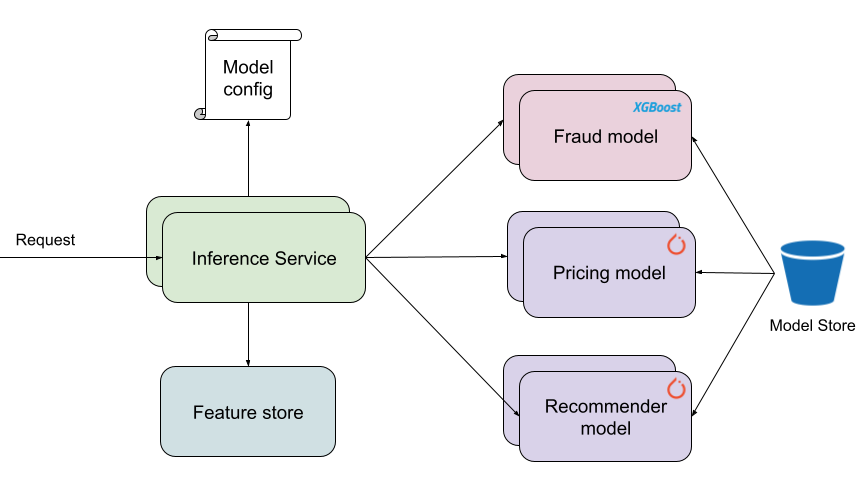
Once the platform has the model artifact and its config, it handles model loading, feature fetching, and other concerns. The high-level components of a general serving system are in figure 2. For simplicity, I’ll assume all services are deployed as containers.
In the general case, a request to the Inference Service may ask for multiple predictions from multiple models. As numbered in figured 2, the steps to service a request are:
- Read the model config for the model(s) in the requests. Then use the config to determine what features to fetch.
- Retrieve features from the feature store. Some features may be included in the request and don’t need to be fetched. If a feature is missing from the feature store or is too stale, use default values.
- Send features to the respective models to get predictions.
- Return predictions back to the client.

The components of the architecture:
- Inference Service — provides the serving API. Clients can send requests to different routes to get predictions from different models. The Inference Service unifies serving logic across models and provides easier interaction with other internal services. As a result, data scientists don’t need to take on those concerns. Also, the Inference Service calls out to ML serving containers to obtain model predictions. That way, the Inference Service can focus on I/O-bound operations while the model serving frameworks focus on compute-bound operations. Each set of services can be scaled independently based on their unique performance characteristics.
- Model Config — is from the platform user. The config for a certain model may be read from another service, or all configs may be loaded into memory when the Inference Service starts.
- Feature store — is one or more data stores that contain features.
- ML serving framework — is a container with all the dependencies required to run a certain type of model. For example, a container with a specific version of Tensorflow Serving. The container may serve one or more models. To ensure reusable images, models usually aren’t baked into the container image. Rather, the container loads in models when it starts, or when a request for that model comes in. After a period of inactivity, models may be evicted from memory.
- Model Store — is exactly what it sounds like. This may be an object store like AWS S3 and services may interact with it via a model registry service.
Not shown in the diagram
Figure 2 is not comprehensive and only represents the core components. All production systems should have monitoring in place for operational metrics. Also, model metrics may flow into another system for drift detection. There could be a component for applying business logic to model predictions, for example, to augment rankings for product recommendations. Each business will need to determine their own needs.
Where does the system live?
Many of the organizations mentioned above chose to deploy the platform on Kubernetes. Some reasons why:
- It helps you manage a large number of containers!
- Resource virtualization. Containers get resource requests and limits, so no single one can hog all the resources, which is useful for serving multiple models from the same instance.
- Horizontal auto-scaling based on CPU utilization and other metrics is easy to configure.
You might not choose Kubernetes for container orchestration but you’ll probably want something similar.
As an example, this is what Reddit’s serving platform looks like:

Scaling to serve more models
At first, it’s simplest to serve one model per set of ML serving framework containers. Figure 4 is an example. The fraud model is in a set of XGBoost containers, the pricing model is in a set of TorchServe containers, and the recommender model is in another set of TorchServe containers. With a good container orchestration framework, you can scale to hundreds of models.

Over time, teams produce more models and multiple versions of the same model type, which results in many containers. You might move towards serving multiple models per container because:
- You want higher resource utilization. If the pricing model is idle, there are still 2 or more running containers to make sure the model is available. These containers take up the requested amount of resources. But, if a TorchServe container serves both the recommender and pricing models, you can use a higher percentage of resources. Of course, the tradeoff is you can have noisy neighbors where one model is slowed down because the other is competing for resources.
- You anticipate you’ll run into some limit on the number of containers. Kubernetes has a per cluster limit and so does AWS Elastic Container Service. Or, maybe the cluster is shared and there’s a limit on the number of containers for the serving platform.
Some frameworks like Tensorflow Serving and TorchServe support serving multiple models natively [1, 5]. Salesforce Einstein serves multiple models per container because they need to serve a super large number of models.

Optimizations
If the system in figure 2 is not performant enough, there are multiple opportunities for optimization.
The first is to add caching. You can add a cache in front of the feature store to speed up feature retrieval. If the serving framework loads a model into memory only when a request comes in, the first request may be slow. One way to speed it up is to add a cache in front of the model store, like a shared file system. If you frequently get identical prediction requests, you can even add a cache for model predictions.
Another optimization is to serve models in C++. DoorDash’s serving platform supports lightGBM and PyTorch models and runs both in C++ [7].
Request batching can be useful if some applications need predictions for many inputs at once. For instance, ranking 100 items for recommendations in a single request. Some serving frameworks support batching multiple prediction requests for better throughput. Batching predictions can be especially beneficial when running neural networks on GPUs since batching takes better advantage of the hardware.
Shadow mode and model rollouts
One way to implement shadow mode is to forward some percentage of production model requests to the shadow model(s). Send the request without waiting on a response, and set up a monitoring system to write shadow model inputs and outputs to an offline store like Snowflake or AWS Redshift. Data scientists can then analyze model performance offline. It’s crucial to give shadow models lower priority than production models to prevent outages. In Kubernetes, you can specify priorities for pod scheduling and eviction [4].
The safe way of rolling out a new version of a model is to first divert a small percentage of production traffic to the new version. There are two ways to do so. The first is to let the client choose which version of a model to use. They can call a different API route or include the model version in the request. The other way to let the platform choose — developers specify how much traffic to send to the new model in the model config or some other config file. The Inference Service is then in charge of routing the right percentage of requests to the new model. I prefer the latter approach since clients don’t need to change their behavior to use a new model.
Serving a super large number of models
Salesforce has a unique use case where they need to serve 100K-500K models because the Salesforce Einstein product builds models for every customer. Their system serves multiple models in each ML serving framework container. To avoid the noisy neighbor problem and prevent some containers from taking significantly more load than others, they use shuffle sharding [8] to assign models to containers. I won’t go into the details and I recommend watching their excellent presentation in [3].

Conclusion
We’ve talked about an architecture used by multiple organizations to serve a large number of models and provide a paved path for teams across the organization. I’m sure there are alternative designs as the specifics of any design depend on the organization’s requirements. Please let me know about other architectures I should look into!
References
- “12. Running TorchServe — PyTorch/Serve Master Documentation.” PyTorch, pytorch.org/serve/server.html#serving-multiple-models-with-torchserve. Accessed 11 Jan. 2022.
- Hoffman, Garrett. “Evolving Reddit’s ML Model Deployment and Serving Architecture.” Reddit, 4 Oct. 2021, www.reddit.com/r/RedditEng/comments/q14tsw/evolving_reddits_ml_model_deployment_and_serving.
- Manoj Agarwal. “Serving ML Models at a High Scale with Low Latency // Manoj Agarwal // MLOps Meetup #48.” YouTube, uploaded by MLOps.community, 22 Jan. 2021, www.youtube.com/watch?v=J36xHc05z-M.
- More, Pratyush. “Catwalk: Serving Machine Learning Models at Scale — Towards Data Science.” Medium, 12 Dec. 2021, towardsdatascience.com/catwalk-serving-machine-learning-models-at-scale-221d1100aa2b.
- “Scheduling, Preemption and Eviction.” Kubernetes, kubernetes.io/docs/concepts/scheduling-eviction. Accessed 11 Jan. 2022.
- “Tensorflow Serving Configuration | TFX |.” TensorFlow, www.tensorflow.org/tfx/serving/serving_config#model_server_configuration. Accessed 11 Jan. 2022.
- Zeng, Cody. “Meet Sibyl — DoorDash’s New Prediction Service — Learn about Its Ideation, Implementation and Rollout.” DoorDash Engineering Blog, 6 Oct. 2020, doordash.engineering/2020/06/29/doordashs-new-prediction-service.
- Zuo, Quinn. “Deploying Large-Scale Fraud Detection Machine Learning Models at PayPal.” Medium, 4 Jan. 2022, medium.com/paypal-tech/machine-learning-model-ci-cd-and-shadow-platform-8c4f44998c78.
- MacCárthaigh, Colm. “Workload Isolation Using Shuffle-Sharding.” Amazon Web Services, Inc., aws.amazon.com/builders-library/workload-isolation-using-shuffle-sharding. Accessed 13 Jan. 2022.

.png)


.png)