

This post was written in collaboration with our sponsors from Flyte
This post was written in collaboration with our sponsors from Flyte.
By Samhita Alla | Software Engineer & Tech Evangelist at Union.ai
So your company is building jaw-dropping machine learning (ML) models that are performant and outputting the best results. The next task is to promote the models to production.
It seems easy. After all, the most complex phase — building ML models — yielded a fruitful result. And shouldn’t it be easy considering how well DevOps (development operations) has matured into a set of practices that can ship software in minutes?
At first glance, DevOps does seem like the go-to choice to push machine learning models to production. But in fact, there’s more to productionizing ML.
DevOps
We’ve been writing software and building applications for a very long time, and we’ve been thinking about its wider deployment for almost as long. DevOps is a structured way to scale and maintain software reliably. Typical DevOps practices include:
- Continuous Integration (CI): Frequently merging code changes
- Continuous Delivery (CD): Continuous promotion from development to staging to production
- Infrastructure as Code (IaC): Managing infrastructure through code
- Monitoring and Logging: Constant monitoring of the deployment
- Communication and Collaboration: Team collaboration, multi-tenancy
- Microservices: Building an application as a set of small services
You may think that if the aforementioned practices aid in the development and deployment of software, they assuredly have to help with the deployment of machine learning models. ML is code after all!
However, it isn’t true.


Unlike software engineering, ML development has multiple branches to deal with. Although the typical DevOps practices are helpful to deploy the models, they just aren’t enough.
MLOps Is a Superset of DevOps
Build models like you build software with a hefty dose of ML-native practices.
MLOps is a combination of machine learning, DevOps, and data engineering. Here’s how MLOps differs from DevOps:
- Models can deteriorate over time. Because models and data are mutable, they require constant iteration and experimentation. Software development isn’t as variable and nondeterministic as ML models. Ensuring ML models climb the performance curve requires additional effort.
- Data may be very complex. In ML, data can be huge. It may need to be pulled from multiple sources.
- Infrastructure overhead & hardware requirements are significant. Models are tied to higher processing and compute power. More often than not, ML models need to run on GPUs, and they rely on more memory than software development does.
- Scale of operations. Scalability of models is crucial for handling the ever-mutating data.
When running models at scale, we’ll also have to take care of:
- Retraining the models on a cadence
- Versioning the data and code
- Data quality
- Monitoring and logging
- Adding tests to CI
Requirements for ML Pipelines
MLOps at large needs to ensure:
- Reproducibility. Determinism of a run. We should be able to reproduce a run given the same set of inputs; this facilitates debugging.
- Recoverability. If there’s a pipeline failure, we should be able to recover from the failure.
- Reliability. A holistic approach to ensure consistency of a pipeline or system.
- Auditability. Ability to backtrack to the error source when a pipeline fails. This in turn leads to data lineage — understanding how the data is transformed over time.
- Adaptability. Dynamism of an ML system. How convenient it is to switch among various ML models within a pipeline.
- Maintainability. A holistic approach to ensure maintenance of ML pipelines, which includes support for iterative development, team collaboration, automation, and more.
MLOps is still a challenge: There’s a wide gap between machine learning and engineering. Deployment of models is a hard nut to crack, primarily because of backend leakage into the data world that data scientists are expected to wrap their heads around.
On the surface, it may seem like it’s the job of data scientists to handle all the MLOps challenges. However, it is unreasonable to expect them to know about low-level infrastructure.

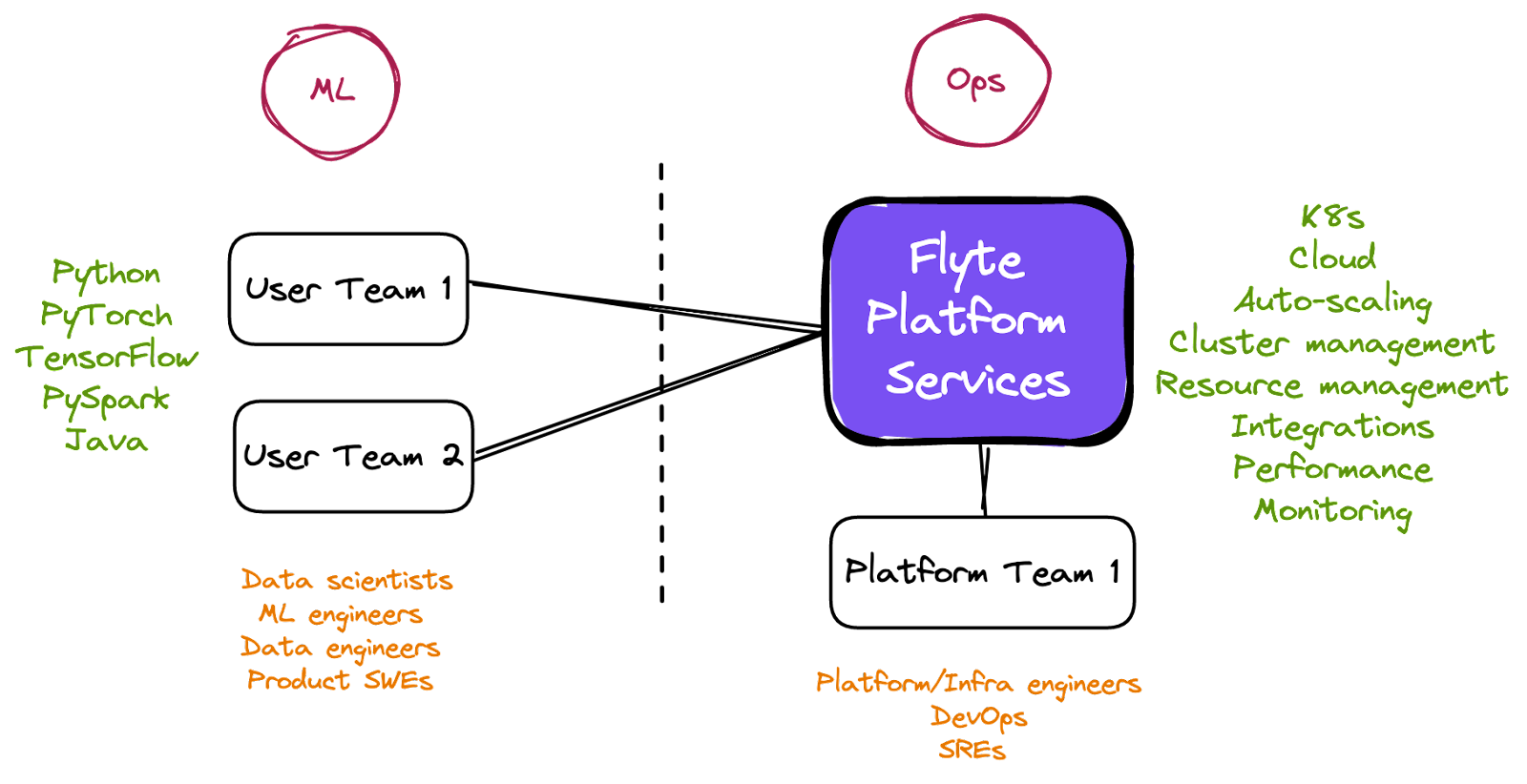
We ought to separate the concerns of the platform/infrastructure team and the user team.
Meet Flyte!
Flyte is a data- and machine learning-aware workflow automation tool built on top of Kubernetes. The goal of Flyte is to provide a reproducible, incremental, iterative, and extensible workflow automation platform-as-a-service (PaaS) for any organization.
The following are the features of Flyte that aim to solve MLOps challenges by converging the workflows between machine learning and engineering:
Note: SDKs for Flytekit (the tool with which you can write Flyte-compatible code) are available in Python, Java, and Scala. This article quotes code snippets that use the Python SDK.
- Separation of concerns between platform and user teams. The immediate MLOps challenge is to incorporate an infrastructure abstraction and workflow automation platform that can separate the responsibilities between the platform and user teams. At the same time, it must unify the teams along the lines of a single platform.
Flyte is adept at enabling segregation of concerns and collaboration of teams.
- Develop incrementally and constantly iterate. An ML model needs to be retrained on a cadence (or sometimes, updated) because data is variable; this requires continuous integration and delivery in place.
Flyte supports the incremental and iterative development of code locally and on production setups (with the same ease as running locally). The promotion of code from local to staging to production can be done with ease using a CI/CD setup, such as GitHub Actions. Flyte also ships with a native scheduler that helps run pipelines regularly and ensure they don’t go stale.
- Infrastructure as Code (IaC)
ML models heavily rely on GPUs, and they may need to be scaled to multiple GPUs if data is huge or training is compute-intensive.
Flyte provides a declarative infrastructure-as-code (IaC) approach to access resources such as CPUs, GPUs, and memory.
@task(limits=Resources(cpu="2", mem="150Mi"))
def pay_multiplier(df: pandas.DataFrame, scalar: int) -> pandas.DataFrame:
df["col"] = 2 * df["col"]
return dfA @task is a fully-independent unit of execution and first-class entity of Flyte. The Resources class accepts “cpu”, “gpu”, “mem”, “storage”, and “ephemeral_storage”.
- Caching, retry, and recovery. Executing ML code requires greater processing power than a typical software application. If your feature engineering component succeeds and the training component fails, you do not want to burn out your resources by running the code right from scratch.
Flyte ships with three interesting features to handle the re-executions, namely, caching, retry, and recovery.
Caching skips re-execution of code if the output of a task is cached, regardless of who ran it in the past. Retry triggers the execution again if the preceding execution fails. The recover option reruns an execution starting from the failed node by copying all the successful task executions.
@task(cache=True, retries=2)
def pay_multiplier(df: pandas.DataFrame, scalar: int) -> pandas.DataFrame:
df["col"] = 2 * df["col"]
return df“cache” can be set to True to cache the output of a @task. The number of retries is an integer.

- Multi-tenancy. Models may need to be used or worked upon by several teams within an organization. A single ML pipeline can comprise several components, each assigned to a team. The team members should be able to share their code and collaborate with other teams when the need arises.
As a Kubernetes-native platform, Flyte is multi-tenant from the ground up.

- Versioning. Versioning is crucial to reproduce ML models and data. Since models and data are mutable, maintaining separate versions is important to enable a switch between the versions and choose the best-performing model.
In Flyte, the entire @workflow (a Flyte entity that captures the dependencies between tasks) is versioned and all the tasks and workflows are immutable.
- Parallelism. Running ML code requires more time than a typical software engineering job. Hence, it’s essential to run the code in parallel whenever possible.
Flyte determines if two nodes can be run in parallel, meaning less wait time for users to get their results.
- Compile-time validation. Rather than catching the errors at run time, it’s beneficial to capture the errors at compile time because ML is compute- and time-expensive.
Flyte’s serialization and registration process have many validations and tests like type enforcement available to users natively.
- Data lineage. When an error pops up, there has to be a mechanism to backtrack to the error source. Moreover, the user should be able to understand the intermediate data (inputs and outputs) at every point in time.
Flyte is a data-aware platform. It understands data in all respects.

- BONUS: Intra-task checkpointing. Checkpointing is an important feature to enable when training ML models because training is expensive. Checkpoints can be helpful: Storing snapshots of the model until the current state allows you to continue subsequent executions from the failed state.
Flyte provides an intra-task checkpointing feature that can be leveraged from within @task. This feature supports the use of AWS spot instances or GCP preemptible instances to lower the costs.
How to Start Adopting Flyte for Your Machine Learning Pipelines
Your company could be using a customized setup to handle ML workflows, or it might be using other orchestration tools. It’s time for you to make the switch to the right workflow orchestration service that caters to all your needs.
Here’s a chronological overview of how you could port your existing ML pipelines to Flyte, which involves the collaboration between user and platform teams to create a consolidated solution. This isn’t a one-size-fits-all solution, but it does include some best practices.
Let’s assume
User team = Data scientists, ML/Data engineers
Platform team = Infrastructure engineers, DevOps engineers
Write an ML job
Team: User
The first step to getting started with building an ML pipeline is to write a job (or @task as per Flyte terminology). The job could be a training job, data preprocessing job, or spark job. If the user team has the code to implement it, they’ll have to convert it to Flyte-compatible code to be able to run it on the Flyte backend. (This requires little refactoring.) If the task interacts with a tool or an external service, the user team can take a look at the supported plugins before implementing the code from scratch.
Run it locally
Team: User
Despite writing the code as per Flyte DSL (domain-specific language), it’s important that the user team can run the code locally. Flyte supports local executions out of the box. After the team constructs Flyte-compatible workflows, it can run the code locally just like how one would run a Python file.
Scale the job
Team: User
Depending on how compute-intensive the tasks are, the user team may need to tune resources to run them on a production setup. Since Flyte provides a declarative IaC approach, the team can use knobs to set the required CPU, GPU, and mem.
Create a pipeline
Team: User
Stitch all the jobs/tasks together to create a pipeline/workflow.
Test the pipeline locally
Team: User
Run the code locally to verify the output.
Set up the Flyte local environment
Team: User
Before the user team tests the code in production, it’s useful to test it on a bare-bones Flyte setup. The Getting Started guide should help the team set up a Kubernetes cluster on their local machines and run the workflows on the Flyte backend. “Kubernetes” might intimidate data scientists; nonetheless, given that Docker, an OS-level virtualization platform, is installed, it should take less than three minutes to get the Flyte workflows up and running on the backend.
Set up Flyte
Team: Platform
Setting up Flyte in production involves configuring the database, object store, authentication, and so on. This can be done on an on-prem setup or in the cloud — be it AWS, GCP, Azure, or any cloud service. The deployment guide in the Flyte documentation should help with setting up a production-ready Flyte backend with a centrally managed infrastructure. The platform team interacts with Flyte directly to ensure that the production environment is functioning properly, and the user team works on the data and models.
Set up DevOps
Team: Platform
To automate the process of packaging code and registering it on the Flyte backend to run the pipeline at scale, it’s important to implement some DevOps practices.
After the user team builds an ML pipeline, the code needs to be packaged and registered on the Flyte backend. This can turn out to be a complex process if it needs to be done for every code or dependency change. Here’s how Lyft roughly handles 1+ million Flyte workflows:
- Every time a new pull request (PR) is created by the user team, a Docker container that captures the dependencies is built from the PR, and the tasks and workflows are registered that will use the Docker image when they run.
- If dependencies are modified by the user team — say, when a new library is to be installed — PR securely builds the container again.
- Straight code changes use fast registration: The code is registered on the Flyte backend without building any Docker image.
- The user team can run the registered tasks and workflows on the Flyte backend (let’s assume the domain is development when testing through a PR).
- Once a PR is merged to the master/main branch, tasks and workflows are promoted to the production domain. The user team can then simulate the deployment through a deployment pipeline.
- At each stage of the deployment, tasks and workflows are registered in Flyte with a specific domain (such as development, staging, and production).
- Logs and metrics are automatically tracked for production deployments.
How to version Flyte tasks and workflows during the registration process? Tasks can be versioned using the GIT-SHA or hash of the entire code artifact. Workflows can be versioned using the GIT-SHA of the containing repository.
Execute the pipeline on-demand
Team: User
After the automation is in place, the user team can test and deploy the ML pipelines with ease.
Schedule workflows
Team: User
Schedules can be created from within the code using LaunchPlan — a plan to execute the workflows.
Retrieve results
Team: User
The user team can retrieve the pipeline’s intermediate or final outputs from a Jupyter notebook using FlyteRemote or from the CLI using Flytectl, or view them via the UI.
Maintenance
Team: Platform
Maintenance includes periodically upgrading Flyte components and ensuring that the Flyte backend is operational.
All the processes together portray a clear picture of how MLOps can be implemented with ease through Flyte.
The convergence of workflows between machine learning and engineering is a longstanding problem that we need to address now. We believe Flyte bridges the gap between the two and adds a lot more ML flavor to the engineering discipline. Flyte aims to unify data scientists, ML engineering, and platform engineers on a single platform by erecting strong interface boundaries. If Flyte interests you, feel free to check out our GitHub, explore our documentation, and join our Slack!
.png)

