
🤖 image generated using the Stable Diffusion 2

As model complexity increases exponentially, so too does the need for effective MLOps practices. This post acts as a transparent write-up of all the MLOps frustrations I’ve experienced in the last few days. By sharing my challenges and insights, I hope to contribute to a community that openly discusses and shares solutions for MLOps challenges.
My goal was to improve Inference latency of few of the current state-of-the-art LLMs.
Unfortunately, simply downloading trained model weights & existing code doesn’t solve this problem.
The Promise of Faster Inference
My first target here was Llama 2. I wanted to convert it into ONNX format, which could then be converted to TensorRT, and finally served using Triton Inference Server.
TensorRT optimizes the model network by combining layers and optimizing kernel selection for improved latency, throughput, power efficiency and memory consumption. If the application specifies, it will additionally optimize the network to run in lower precision, further increasing performance and reducing memory requirements.
From online benchmarks [1, 2] it seems possible to achieve a 2~3x boost to latency (by reducing precision without hurting quality much). But the workings for these kind of format conversions feel super flaky, things break too often (without any solution to be found online). Yes, it’s somewhat expected since these models are so new, with different architectures using different (not yet widely-supported) layers and operators.
Model Conversion Errors
Let’s start with Llama 2 7B chat,
- Firstly I’ve downloaded Llama-2-7B-Chat weights from Meta’s Official repository here after requesting.
- Convert raw weights to huggingface format using this script by Huggingface. Let’s say we save it under
llama-2-7b-chat-hfdirectory locally.
Now I considered two options for converting Huggingface models to ONNX format:
torch.onnx.export gibberish text
Let’s write an export_to_onnx function which will load the tokenizer & model, and export it into ONNX format:
import torch
from composer.utils import parse_uri, reproducibility
from pathlib import Path
from transformers import AutoConfig, AutoModelForCausalLM, AutoTokenizer
def export_to_onnx(
pretrained_model_name_or_path: str,
output_folder: str,
verify_export: bool,
max_seq_len: int | None = None,
):
reproducibility.seed_all(42)
_, _, parsed_save_path = parse_uri(output_folder)
# Load HF config/model/tokenizer
tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name_or_path, use_fast=True)
config = AutoConfig.from_pretrained(pretrained_model_name_or_path)
if hasattr(config, 'attn_config'):
config.attn_config['attn_impl'] = 'torch'
model = AutoModelForCausalLM.from_pretrained(pretrained_model_name_or_path, config=config).to("cuda:0")
model.eval()
# tips: https://huggingface.co/docs/transformers/v4.31.0/en/model_doc/llama2
tokenizer.add_special_tokens({"pad_token": "<pad>"})
model.resize_token_embeddings(len(tokenizer))
model.config.pad_token_id = tokenizer.pad_token_id
sample_input = tokenizer(
"Hello, my dog is cute",
padding="max_length",
max_length=max_seq_len or model.config.max_seq_len,
truncation=True,
return_tensors="pt",
add_special_tokens=True).to("cuda:0")
with torch.no_grad():
model(**sample_input)
output_file = Path(parsed_save_path) / 'model.onnx'
output_file.parent.mkdir(parents=True, exist_ok=True)
# Put sample input on cpu for export
sample_input = {k: v.cpu() for k, v in sample_input.items()}
model = model.to("cpu")
torch.onnx.export(
model,
(sample_input,),
str(output_file),
input_names=['input_ids', 'attention_mask'],
output_names=['output'],
opset_version=16)We can also check if the exported & original models’ outputs are similar:
# (Optional) verify onnx model outputs
import onnx
import onnx.checker
import onnxruntime as ort
with torch.no_grad():
orig_out = model(**sample_input)
orig_out.logits = orig_out.logits.cpu() # put on cpu for export
_ = onnx.load(str(output_file))
onnx.checker.check_model(str(output_file))
ort_session = ort.InferenceSession(str(output_file))
for key, value in sample_input.items():
sample_input[key] = value.cpu().numpy()
loaded_model_out = ort_session.run(None, sample_input)
torch.testing.assert_close(
orig_out.logits.detach().numpy(),
loaded_model_out[0],
rtol=1e-2,
atol=1e-2,
msg=f'output mismatch between the orig and onnx exported model')
print('Success: exported & original model outputs match')Assuming we’ve saved the ONNX model in ./llama-2-7b-onnx/, we can now run inference using onnxruntime:
import onnx
import onnx.checker
import onnxruntime as ort
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
output_file = 'llama-2-7b-onnx/model.onnx' # converted model from above
ort_session = ort.InferenceSession(str(output_file))
tokenizer = AutoTokenizer.from_pretrained("llama-2-7b-chat-hf", use_fast=True)
tokenizer.add_special_tokens({"pad_token": "<pad>"})
inputs = tokenizer(
"Hello, my dog is cute",
padding="max_length",
max_length=1024,
truncation=True,
return_tensors="np",
add_special_tokens=True)
loaded_model_out = ort_session.run(None, inputs.data)
tokenizer.batch_decode(torch.argmax(torch.tensor(loaded_model_out[0]), dim=-1))😖 On my machine, this generates really funky outputs:
ЉЉЉЉЉЉ\n\n\n\n\n\n\n\n\n\n Hello Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis Hinweis..........SMSMSMSMSMSMSMSMSMSMSMS Unterscheidung, I name is ough,… which is mostly due to missing a proper decoding strategy (greedy, beam, etc.) while generating tokens.
optimum-cli gibberish text and tensorrt slowness
To solve the problem above, we can try a different exporter which includes decoding strategies.
Using the Optimum ONNX exporter instead (assuming the original model is in ./llama-2-7b-chat-hf/), we can do:
optimum-cli export onnx \
--model ./llama-2-7b-chat-hf/ --task text-generation --framework pt \
--opset 16 --sequence_length 1024 --batch_size 1 --device cuda --fp16 \
llama-2-7b-optimum/⌛ This takes a few minutes to generate. If you don’t has a GPU for this conversion, then remove --device cuda from the above command.
The result is:
llama-2-7b-optimum
├── config.json
├── Constant_162_attr__value
├── Constant_170_attr__value
├── decoder_model.onnx
├── decoder_model.onnx_data
├── generation_config.json
├── special_tokens_map.json
├── tokenizer_config.json
├── tokenizer.json
└── tokenizer.modelNow when I try to do inference using optimum.onnxruntime.ORTModelForCausalLM, things work fine (though slowly) using the CPUExecutionProvider:
from transformers import AutoTokenizer
from optimum.onnxruntime import ORTModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("./onnx_optimum")
model = ORTModelForCausalLM.from_pretrained("./onnx_optimum/", use_cache=False, use_io_binding=False)
inputs = tokenizer("My name is Arthur and I live in", return_tensors="pt")
gen_tokens = model.generate(**inputs, max_length=16)
assert model.providers == ['CPUExecutionProvider']
print(tokenizer.batch_decode(gen_tokens))After waiting a long time, we get a result:
<s> My name is Arthur and I live in a small town in the countrBut when switching to the faster CUDAExecutionProvider, I get gibberish text on inference:
model = ORTModelForCausalLM.from_pretrained("./onnx_optimum/", use_cache=False, use_io_binding=False, provider="CUDAExecutionProvider")
inputs = tokenizer("My name is Arthur and I live in", return_tensors="pt").to("cuda")
gen_tokens = model.generate(**inputs, max_length=16)
assert model.providers == ['CUDAExecutionProvider', 'CPUExecutionProvider']
print(tokenizer.batch_decode(gen_tokens))2023-08-02 19:47:43.534099146 [W:onnxruntime:, session_state.cc:1169 VerifyEachNodeIsAssignedToAnEp]
Some nodes were not assigned to the preferred execution providers which may or may not
have an negative impact on performance. e.g. ORT explicitly assigns shape related ops
to CPU to improve perf.
2023-08-02 19:47:43.534136078 [W:onnxruntime:, session_state.cc:1171 VerifyEachNodeIsAssignedToAnEp]
Rerunning with verbose output on a non-minimal build will show node assignments.
<s> My name is Arthur and I live in a<unk><unk><unk><unk><unk><unk>Even with different temperature and other parameter values, it always yields unintelligible outputs, as reported in optimum#1248.
🎉 Update: after about a week this issue seemed to magically disappear — possibly due to a new version of llama-2-7b-chat-hf being released.
Using the new model with max_length=128, :
Prompt: Why should one run Machine learning model on-premises?
ONNX inference latency:
2.31sHuggingFace version latency:
3s
🚀 The ONNX model is ~23% faster than the HuggingFace variant!
⚠️ However, while both CPU and CUDA providers work, there now seems to be a bug when trying TensorrtExecutionProvider — reported in optimum#1278.
optimum-cli segfaults
Next let’s try with the Dolly-v2 7B from Databricks. The equivalent optimum-cli command for ONNX conversion would be:
optimum-cli export onnx \
--model 'databricks/dolly-v2-7b' --task text-generation --framework pt \
--opset 17 --sequence_length 1024 --batch_size 1 --fp16 --device cuda \
dolly_optimum😢 It uses around 17GB of my GPU RAM, seemingly working fine but finally ending with a segmentation fault:
======= Diagnostic Run torch.onnx.export version 2.1.0.dev20230804+cu118 =======
verbose: False, log level: 40
======================= 0 NONE 0 NOTE 0 WARNING 0 ERROR ========================
Saving external data to one file...
2023-08-09 20:59:33.334484259 [W:onnxruntime:, session_state.cc:1169 VerifyEachNodeIsAssignedToAnEp]
Some nodes were not assigned to the preferred execution providers which may or may not
have an negative impact on performance. e.g. ORT explicitly assigns shape related ops
to CPU to improve perf.
2023-08-09 20:59:33.334531829 [W:onnxruntime:, session_state.cc:1171 VerifyEachNodeIsAssignedToAnEp]
Rerunning with verbose output on a non-minimal build will show node assignments.
Asked a sequence length of 1024, but a sequence length of 1 will be used with
use_past == True for `input_ids`.
Post-processing the exported models...
Segmentation fault (core dumped)Confusingly, despite this error, all model files seem to be converted and saved to disk. Other people have reported similar segfault issues while exporting (transformers#21360, optimum#798).
Results using the Dolly v2 model:
Prompt: Why should one run Machine learning model on-premises?
ONNX inference latency:
8.2sHuggingFace version latency:
5.2s
😠 The ONNX model is actually ~58% slower than the HuggingFace variant!
To make things faster, we can try to optimize the model:
optimum-cli onnxruntime optimize -O4 --onnx_model ./dolly_optimum/ -o dolly_optimized/The different optimization levels are:
-O1: basic general optimizations.-O2: basic and extended general optimizations, transformers-specific fusions.-O3: same as O2 with GELU approximation.-O4: same as O3 with mixed precision (fp16, GPU-only).
We still get the same segfault error for all of the levels.
For -O1, the model gets saved but there’s no noticeable performance change. For -O2 it gets killed (even though I have 40GB A100 GPU + 80GB CPU RAM). Meanwhile for -O3 & -O4 it gives seg-fault (above) while only partially saving the model files.
torch.onnx.export gibberish images
Moving on from text-based models, let’s now look at an image generator. We can try to speed up the Stable Diffusion 2.1 model. In an IPython shell:
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-1", torch_dtype=torch.float16).to("cuda:0")
%time img = pipe("Iron man laughing", num_inference_steps=20, num_images_per_prompt=1).images[0]
img.save("iron_man.png", format="PNG")The latency (as measured by the %time magic) is 3.25 s.
To convert to ONNX format, we can use this script:
python convert_stable_diffusion_checkpoint_to_onnx.py \
--model_path stabilityai/stable-diffusion-2-1 \
--output_path sd_onnx/ --opset 16 --fp16ℹ️ Note: if a model uses operators unsupported by the opset number above, you'll have to upgrade pytorch to the nightly build:
pip uninstall torch
pip install --pre torch --index-url https://download.pytorch.org/whl/nightly/cu121The result is:
sd_onnx/
├── model_index.json
├── scheduler
│ └── scheduler_config.json
├── text_encoder
│ └── model.onnx
├── tokenizer
│ ├── merges.txt
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ └── vocab.json
├── unet
│ ├── model.onnx
│ └── weights.pb
├── vae_decoder
│ └── model.onnx
└── vae_encoder
└── model.onnxThere’s a separate ONNX model for each Stable Diffusion subcomponent model.
Now to benchmark this similarly we can do the following:
from diffusers import OnnxStableDiffusionPipeline
pipe = OnnxStableDiffusionPipeline.from_pretrained("sd_onnx", provider="CUDAExecutionProvider")
%time img = pipe("Iron man laughing", num_inference_steps=20, num_images_per_prompt=1).images[0]
img.save("iron_man.png", format="PNG")The overall performance results look great, at ~59% faster! We also didn’t see any noticeable quality difference between the models.
Prompt: Iron man laughing
ONNX inference latency:
1.34sHuggingFace version latency:
3.25s
Since we know that the unet model is the bottleneck, taking ~90% of the compute time, we can focus on it for further optimization. We try to serialize the ONNX version of the UNet to a TensorRT engine-compatible format. When building the engine, the builder object selects the most optimized kernels for the chosen platform and configuration. Building the engine from a network definition file can be time-consuming, and should not be repeated each time we need to perform inference unless the model/platform/configuration changes. You can transform the format of the engine after generation and save it to disk for later reuse (known as serializing the engine). Deserializing occurs when you load the engine from disk into memory:
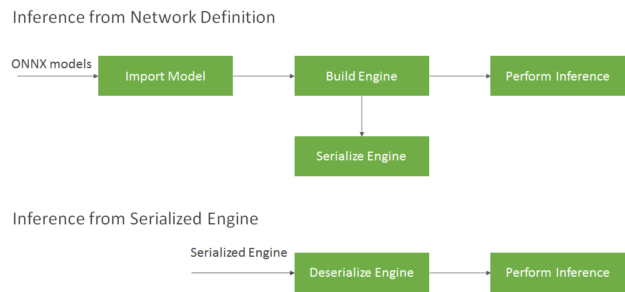
To setup TensorRT properly, follow this support table. It’s a bit painful, and (similar to cuda/cudnn) if you just want a quick solution you can use NVIDIA’s tensorrt:22.12-py3 docker image as a base:
FROM nvcr.io/nvidia/tensorrt:22.12-py3
ENV CUDA_MODULE_LOADING=LAZY
RUN pip install ipython transformers optimum[onnxruntime-gpu] onnx diffusers accelerate scipy safetensors composer
RUN pip uninstall torch -y && pip install --pre torch --index-url https://download.pytorch.org/whl/nightly/cu121
COPY sd_onnx sd_onnxWe can then use the following script for serialization:
import tensorrt as trt
import torch
onnx_model = "sd_onnx/unet/model.onnx"
engine_filename = "unet.trt" # saved serialized tensorrt engine file path
# constants
batch_size = 1
height = 512
width = 512
latents_shape = (batch_size, 4, height // 8, width // 8)
# shape required by Stable Diffusion 2.1's UNet model
embed_shape = (batch_size, 64, 1024)
timestep_shape = (batch_size,)
TRT_LOGGER = trt.Logger(trt.Logger.INFO)
TRT_BUILDER = trt.Builder(TRT_LOGGER)
network = TRT_BUILDER.create_network(1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
config = TRT_BUILDER.create_builder_config()
profile = TRT_BUILDER.create_optimization_profile()
print("Loading & validating ONNX model")
onnx_parser = trt.OnnxParser(network, TRT_LOGGER)
parse_success = onnx_parser.parse_from_file(onnx_model)
for idx in range(onnx_parser.num_errors):
print(onnx_parser.get_error(idx))
if not parse_success:
raise ValueError("ONNX model parsing failed")
# set input, latent and other shapes required by the layers
profile.set_shape("sample", latents_shape, latents_shape, latents_shape)
profile.set_shape("encoder_hidden_states", embed_shape, embed_shape, embed_shape)
profile.set_shape("timestep", timestep_shape, timestep_shape, timestep_shape)
config.add_optimization_profile(profile)
config.set_flag(trt.BuilderFlag.FP16)
print(f"Serializing & saving engine to '{engine_filename}'")
serialized_engine = TRT_BUILDER.build_serialized_network(network, config)
with open(engine_filename, 'wb') as f:
f.write(serialized_engine)Now let’s move to deserializing unet.trt for inference. We’ll use the TRTModel class from x-stable-diffusion’s trt_model:
import torch
import tensorrt as trt
trt.init_libnvinfer_plugins(None, "")
import pycuda.autoinit
from diffusers import AutoencoderKL, LMSDiscreteScheduler
from PIL import Image
from torch import autocast
from transformers import CLIPTextModel, CLIPTokenizer
from trt_model import TRTModel
from tqdm.contrib import tenumerate
class TrtDiffusionModel:
def __init__(self):
self.device = torch.device("cuda")
self.unet = TRTModel("./unet.trt") # tensorrt engine saved path
self.vae = AutoencoderKL.from_pretrained(
"stabilityai/stable-diffusion-2-1", subfolder="vae").to(self.device)
self.tokenizer = CLIPTokenizer.from_pretrained(
"stabilityai/stable-diffusion-2-1", subfolder="tokenizer")
self.text_encoder = CLIPTextModel.from_pretrained(
"stabilityai/stable-diffusion-2-1", subfolder="text_encoder").to(self.device)
self.scheduler = LMSDiscreteScheduler(
beta_start=0.00085,
beta_end=0.012,
beta_schedule="scaled_linear",
num_train_timesteps=1000)
def predict(
self, prompts, num_inference_steps=50, height=512, width=512, max_seq_length=64
):
guidance_scale = 7.5
batch_size = 1
text_input = self.tokenizer(
prompts,
padding="max_length",
max_length=max_seq_length,
truncation=True,
return_tensors="pt")
text_embeddings = self.text_encoder(text_input.input_ids.to(self.device))[0]
uncond_input = self.tokenizer(
[""] * batch_size,
padding="max_length",
max_length=max_seq_length,
return_tensors="pt")
uncond_embeddings = self.text_encoder(uncond_input.input_ids.to(self.device))[0]
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
latents = torch.randn((batch_size, 4, height // 8, width // 8)).to(self.device)
self.scheduler.set_timesteps(num_inference_steps)
latents = latents * self.scheduler.sigmas[0]
with torch.inference_mode(), autocast("cuda"):
for i, t in tenumerate(self.scheduler.timesteps):
latent_model_input = torch.cat([latents] * 2)
sigma = self.scheduler.sigmas[i]
latent_model_input = latent_model_input / ((sigma**2 + 1) ** 0.5)
# predict the noise residual
inputs = [
latent_model_input,
torch.tensor([t]).to(self.device),
text_embeddings]
noise_pred = self.unet(inputs, timing=True)
noise_pred = torch.reshape(noise_pred[0], (batch_size*2, 4, 64, 64))
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (
noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred.cuda(), t, latents)["prev_sample"]
# scale and decode the image latents with VAE
latents = 1 / 0.18215 * latents
image = self.vae.decode(latents).sample
return image
model = TrtDiffusionModel()
image = model.predict(
prompts="Iron man laughing, real photoshoot",
num_inference_steps=25,
height=512,
width=512,
max_seq_length=64)
image = (image / 2 + 0.5).clamp(0, 1)
image = image.detach().cpu().permute(0, 2, 3, 1).numpy()
images = (image * 255).round().astype("uint8")
pil_images = [Image.fromarray(image) for image in images]
pil_images[0].save("image_generated.png")The above script runs, but the generated output looks like this:

Something’s going wrong, and changing to different tensor shapes (defined above) also doesn’t help fix the generation of blank/noisy images.
I don’t know how to make Stable Diffusion 2.1 work with TensorRT, though it’s proved possible for other Stable Diffusion variants in AUTOMATIC1111/stable-diffusion-webui. Others reporting similar issues in stable-diffusion-webui#5503 have suggested:
- Use more than 16-bits: I did, but it didn’t help.
- Use
xformers: For our model we needpytorch‘s recently addedscaled_dot_product_attentionoperator.
Other Frustrations
Maybe the code above is partially in my control, but there are also other issues that have nothing to do with my code:
- Licences: Text Generation Inference recently they came up with a new license which is more restrictive for newer versions. I can only use old releases (up to v0.9).
- Lack of GPU support: GGML doesn’t currently support GPU inference, so I can’t use it if I want very low latency.
- Quality: I’ve heard from peers that saw a big decrease in output quality vLLM. I’d like to explore this in future.
Conclusion
I’ve listed my recent errors and frustrations. I need more time to dig deeper and solve them, but if you think you can help please do reply in any of the issues linked above! By sharing my experiences and challenges, I hope this can spark lots of discussions and new ideas. Maybe you’ve faced something similar?
While the world likes showcasing the latest advancements and shiny results, it’s important to also acknowledge and address the underlying complexities that come with deploying & maintaining ML models. There’s a scarcity of documentation/resources for these problems in the ML community. As the field continues to rapidly evolve, there is a need for more in-depth discussions and solutions to these technical hurdles.



.png)