
In the vast expanse of today’s data-driven world, finding specific information can be like searching for a needle in a haystack
In the vast expanse of today’s data-driven world, finding specific information can be like searching for a needle in a haystack. Imagine that you have a huge dataset, such as Wikipedia pages detailing Marvel movies and TV shows, and you need to find specific information — for instance, details about the parents of Tony Stark (Iron Man). Sifting through countless pages is daunting and inefficient. This is where the power of semantic search comes into play. Semantic search systems, shown in image 1 below, are designed to understand the context and semantics of your query, offering you precise information without the hassle of endless scrolling.
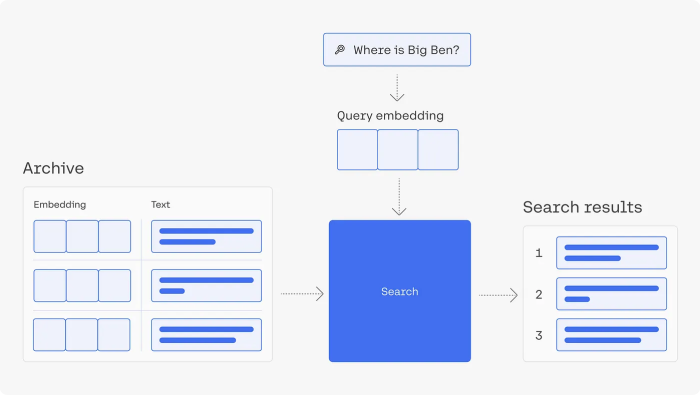
Let’s continue with our Ironman example from the Marvel dataset. Imagine a scenario where a fellow fan is curious about the intricate details of Tony Stark’s character development throughout the Marvel Cinematic Universe. A traditional keyword-based search might return a mix of general Iron Man movie summaries or unrelated character profiles. For example, searching for Ironman character development won’t return results about Tony Stark, but may return results without much context around it. However, with a sophisticated semantic search system, the fan can query something as specific as “Tony Stark’s character evolution in the MCU” and receive targeted, context-rich results. This precision brings the user directly to the most relevant scenes, dialogues, and character arcs, offering a tailored and enriched fan experience.
Now, one may ask: How does it work, technically? Where should we store a large amount of unstructured data so that it can be easily queried and information can be retrieved from it? To answer these questions, I worked on an example project in which I gathered a collection of research papers and abstracts. I then created a semantic search engine capable of addressing my queries about these research papers. My goals were twofold. First, I wanted to understand how the system works behind the scenes and how it is an upgrade from a simple keyword-based search. Second, I wanted to see how different tools like LLMs and vector databases can be used to create a semantic search application.
Here are some technical nitty-gritty details of this project:
- Dataset: https://paperswithcode.com/dataset/arxiv-10
- Database: Milvus-lite vector database
- Text embeddings: Cohere Embed
At the heart of semantic search is data representation. To make unstructured data accessible for machines to read, it needs to be represented in a numerical or vector format. This is where vector databases come in handy. Let’s explore what a vector database is.
Vector Databases
What is a vector database? Simply put, a vector database is a database that stores vector representation of unstructured data and enables search and information retrieval of the data, along with metadata, in an efficient manner. This blog on vector databases provides more technical details. In this project, I have used Milvus-lite, a lightweight version of the Milvus vector database. I chose Milvus for the following reasons:
- It’s an open-source vector database
- It’s a powerful tool to use for applications like semantic search, given the dense nature of the dataset that contains millions of vectors
- Its architecture is distributed, enabling horizontal scalability that separates storage and computing
- Milvus-lite helps get you started quickly
Here’s how I got started:
# Store the dataset in Milvus db
# Declare the required variables like collection name etc.
COLLECTION_NAME = "arxiv_10000"
DIMENSION = 1024
BATCH_SIZE = 128
TOPK = 5
COUNT = 10000
# Connect to the milvus server
from milvus import default_server
from pymilvus import connections, utility
default_server.start()
connections.connect(host = "127.0.0.1", port = default_server.listen_port)
utility.get_server_version()
# Check if the collection is already available, if yes, then drop it and create a new one
if utility.has_collection(COLLECTION_NAME):
utility.drop_collection(COLLECTION_NAME)Here, I defined the schema of the collection to put in the vector database. I made “id” the primary key, added the title, abstract, and label (describes the category the paper falls into, for example, ‘physics’) columns from the dataset, and set their maximum length. Initially, I had arbitrarily set these values, but when I tried to run the entire code, I got errors. The best way to tackle this would be to calculate the max_length of the columns separately and then initialize it in the schema.
# object should be inserted in the format of (title, date, location, speech embedding)
fields = [
FieldSchema(name = "id", dtype = DataType.INT64, is_primary = True, auto_id = True),
FieldSchema(name = "title", dtype = DataType.VARCHAR, max_length = 800),
FieldSchema(name = "abstract", dtype = DataType.VARCHAR, max_length = 9000),
FieldSchema(name = "label", dtype = DataType.VARCHAR, max_length = 20),
FieldSchema(name = "embedding", dtype = DataType.FLOAT_VECTOR, dim = DIMENSION)
]
schema = CollectionSchema(fields = fields)
collection = Collection(name = COLLECTION_NAME, schema = schema)The next step was to initialize the index. To search or query anything in the database, you need an index. In this specific case, the choice was to implement the IVF_FLAT (Inverted File Index) because it offers faster search times, particularly with high-dimensional data like that used in this project. We used the IVF_FLAT index type, especially since I ran this on a CPU. Vector indexes like IVF_FLAT (inverted file index) are employed for approximate nearest neighbor (ANN) search algorithms, which aim to locate the closest points in a high-dimensional space. Here are the top resources that explain ANN in more detail:
- Activeloop’s article provides a simple definition of how ANN works and has more reading resources to understand the algorithm in detail. https://www.activeloop.ai/resources/glossary/approximate-nearest-neighbors-ann/
- In this Zilliz’s article, they mentioned when to use ANN along with a straightforward explanation of the algorithm: https://zilliz.com/glossary/anns
To calculate the similarity distance between the target input and the center of each cluster, the distance metric used was L2, which is the Euclidean distance. I set `nlist` to 100 (as seen in the following code snippet) as I had over 8K records of data, so I wanted to divide the data into 100 clusters.
# Create the index
index_params = {
"index_type": "IVF_FLAT",
"metric_type": "L2",
"params": {"nlist": 100},
}
collection.create_index(field_name = "embedding", index_params = index_params)
collection.load()Once the database was ready, the next step was to create the vector embeddings of the dataset. Here, I called Cohere’s client since I used Cohere’s new version of the Embed model. Before I get into the code, let’s discuss Cohere’s embedding model.
Here are the reasons why I chose to use the Cohere Embed model:
- Enables much faster search capabilities
- Returns better quality of matched responses
- Its new compression-aware training method helps reduce the cost of running vector databases
To give a rough idea of pricing, I embedded just the 10,000 abstracts column from the dataset which equaled 22,315,570 tokens and cost me $2.232 (1,000,000 tokens/$1.00).
Here, I used Cohere’s client API because I used the new version of Cohere’s Embed model:
cohere_client = cohere.Client("enter-your-API-key")#prod key
# Extract embeddings from questions using Cohere
def embed(texts):
res = cohere_client.embed(texts, model = "embed-english-v3.0", input_type = "search_document")
return res.embeddingsIn this version of the Embed model, there is an extra parameter, `input_type`, where you tell the function whether you are embedding a search document or a search query. This additional parameter ensures the highest quality of the user search query and performs more efficiently. Once the embeddings are ready, you must insert them into the collection you created above.
for batch in tqdm(np.array_split(arxiv, (COUNT/BATCH_SIZE) + 1)):
#titles =
abstracts = batch['abstract'].tolist()
data = [
batch['title'].tolist(),
abstracts,
batch['label'].tolist(),
embed(abstracts)
]
collection.insert(data)
# Flush at the end to make sure all rows are sent for indexing
collection.flush()Note that I have just embedded the abstract since the search I intend to do is to ask about a bunch of papers on topics that are included in the dataset. Once the core of the application was set, the next step was to provide the list of search terms, call the `embed` function, and wait for the results.
import time
search_terms = ["What papers talk about astrophysics?", "What are the papers on that discuss computer architecture?"]
# Search the database based on input text
def embed_search(data):
embeds = cohere_client.embed(data, model = "embed-english-v3.0", input_type = "search_query")
return [x for x in embeds]
search_data = embed_search(search_terms)
start = time.time()
res = collection.search(
data = search_data, # Embed search value
anns_field = "embedding", # Search across embeddings
param = {"metric_type": "L2",
"params": {"nprobe": 20}},
limit = TOPK, # Limit to top_k results per search
output_fields = ["title","abstract"] # Include title field in result
)
end = time.time()
for hits_i, hits in enumerate(res):
print("Query:", search_terms[hits_i])
#print("Abstract:", search_terms[hits_i])
print("Search Time:", end-start)
print("Results:\n")
for hit in hits:
print( hit.entity.get("title"), "----", round(hit.distance, 3))
print()
print( hit.entity.get("abstract"), "----", round(hit.distance, 3))
print()
print()The setup is straightforward. I wanted to see the title of the paper and abstract that are the most similar to the search term. If you recall, when I declared the variables before creating the collection, I had set the value of `topK = 5` since I wanted to see the top five answers to my search term. The model returns the similarity score, along with the results, and ranks the results accordingly. Image 2 shows a sample result returned from this model:

The overall process of building semantic search applications is simple, especially with all the tutorials out there. It does take some trial and error to understand what is going on in the code fully. Is my code perfect? No. There is a large scope for improvement, for example:
- Playing with the values of `nlist` and `nprobe`
- Using a larger version of the Embed model
- Adding more data
- Adding a RAG component to the application
If you’re interested in building your semantic search system, I’d strongly recommend that you start simple, and then build upon new features step by step. For the entire code, check out my GitHub repository.



.png)