
A tutorial on prompt-tuning and p-tuning using NeMo alongside W&B, complete with an experiment and executable code
A tutorial on prompt-tuning and p-tuning using NeMo alongside W&B, complete with an experiment and executable code.

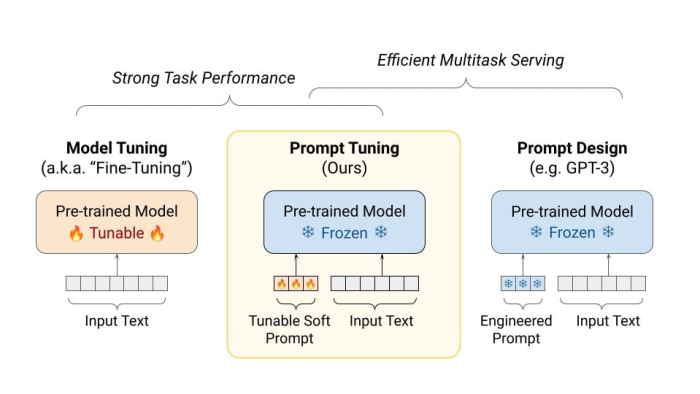
Why Prompt-Tune Instead of Fine-Tune?
Let’s start with a thought experiment:
Imagine you’re the owner of a vast library that contains millions of books. Over the years, you’ve meticulously organized this library, placing each book on its designated shelf, in its specific corner. This library is akin to a pre-trained language model like GPT, and the books represent the knowledge and intricacies learned during its training.
Now, let’s say you have a regular visitor, Alice, who’s writing a research paper on a niche topic – “The Influence of Renaissance Art on Modern Pop Culture” and she can’t find a book in your library that specifically addresses this unique intersection. Instead of reorganizing your entire library or buying hundreds of new books to cater to Alice’s request (akin to fine-tuning), you opt for a more efficient solution: you prepare a custom reading guide for Alice.
This guide lists a sequence of books and chapters she should read in a particular order, along with some notes and questions to prompt her thinking (akin to prompt learning). In this case, you’ve tailored the resources of your library to Alice’s specific needs without altering the fundamental structure or risking the disorganization of other books (avoiding catastrophic forgetting). If another researcher, Bob, comes in next week with a different request, you can prepare a separate guide for him without invalidating Alice’s guide.
This is the essence of prompt-tuning: Instead of changing the core structure (i.e., fine-tuning the model parameters), you’re providing specific guidance (prompts) that tailors the model’s response to a particular task. This process is efficient, adaptable, and avoids many of the issues associated with fine-tuning.
Using tools like NVIDIA NeMo and Weights & Biases, prompt-tuning becomes even more straightforward and effective. The flexibility to insert continuous or virtual tokens means we can adapt our models to a multitude of tasks without the risks and computational costs associated with restructuring the entire model.
So, as we dive deeper into the intricacies of prompt tuning using NeMo, always remember our library analogy. It’s not about restructuring the entire library; it’s about guiding its use in the most efficient way possible.
And lastly, if you’d like to check out the code associated with this post, this GitHub repo has you covered.
Understanding Prompt Tuning and P-Tuning
Let’s journey back to our grand library, packed with millions of books.
Prompt Tuning:
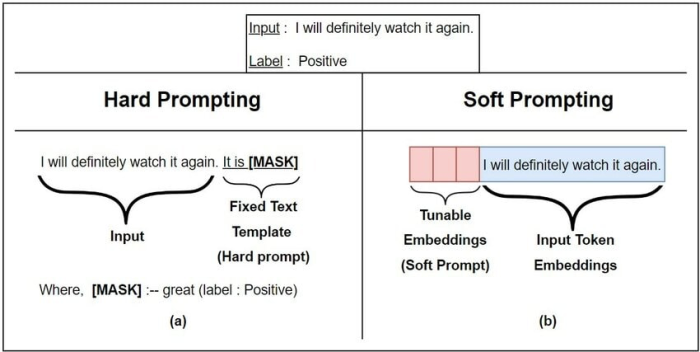
Imagine you’ve prepared several special reading desks for researchers. On each desk, you have a curated stack of reference cards (akin to soft prompt embeddings) for different topics. Whenever a researcher, like Alice, comes in with a unique request, you don’t shuffle the entire library. Instead, you provide her with a stack that’s best suited to her topic. This stack helps her navigate the vast library efficiently.
These stacks (soft prompt embeddings) can be generated in two ways:
- Random Initialization: This is like creating a new set of reference cards based on intuition.
- Initialization from Existing Vocabulary: Think of this as curating the best reference cards based on previously known facts or topics. You pick snippets from established books or notes (existing vocabulary embeddings) and use them to create the guide.
Regardless of the method used, the core library remains untouched, ensuring its vast knowledge remains consistent.
P-tuning:
Now, imagine having a wise librarian assistant, equipped with a journal (akin to the LSTM model). Whenever a researcher poses a question, the assistant swiftly jots down a sequence of book titles and notes in this journal. As more researchers come in with varied queries, the assistant keeps updating this journal. Here, the journal represents the LSTM’s ability to predict the right sequence of virtual tokens for each specific task, ensuring that each researcher gets a customized list without disturbing the others.
Unlike prompt tuning where each topic has its unique stack of cards, p-tuning ensures that there’s a shared understanding, but the journal’s entries are unique for every researcher’s query. This methodology might be particularly beneficial when topics overlap, allowing for shared insights.
Integrating Both Methods:
Your library can simultaneously operate both systems. While one desk has these curated stacks of reference cards, your librarian assistant with the journal can still guide other researchers. Once the assistant has helped enough researchers, the key insights from the journal can be transferred to new reference stacks, preserving the wisdom without the need to always consult the journal.
In terms of computational weight, prompt tuning is like adding a few more reference cards, while p-tuning is akin to the effort and wisdom that goes into maintaining the journal. But thanks to efficient systems like our prompt_table, the heavy lifting during the research phase (training) doesn’t burden the future library visits (inference).
Comparing Cost Performance for Fine-Tuning:

If we were to consider fine-tuning in our library scenario, it would be like buying and integrating many new books or even reorganizing entire sections based on the current trend of research topics. This might benefit a few, but it risks the clarity and order of the library that caters to a broader audience.
While prompt tuning and p-tuning offer different approaches, they ensure that the core knowledge remains undisturbed, and researchers get the best guidance tailored to their needs. As with many things, the choice between methods depends on the specific requirements and challenges at hand.
A Technical Deep Dive into Prompt Tuning and P-Tuning
Let’s unpack the mechanics behind prompt tuning and p-tuning.
Prompt Tuning Mechanics:
Soft Prompt Embeddings
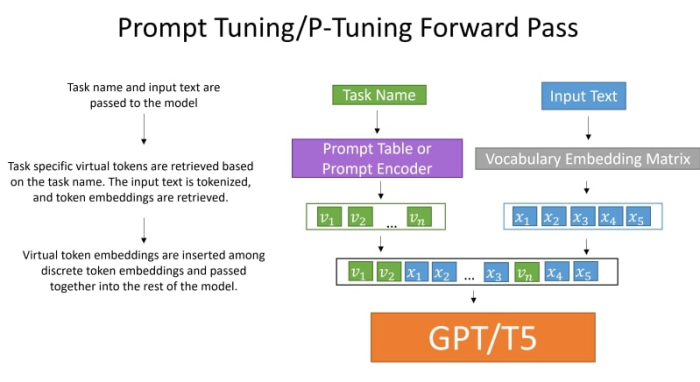
In prompt tuning, we introduce soft prompt embeddings. These are essentially 2D matrices, sized total_virtual_tokens X hidden_size. It’s a flexible mechanism wherein each specific task gets its own matrix. During the training phase, the original GPT parameters remain static; only these embeddings are updated.
Initialization
Random Initialization: The soft prompt embeddings can be initialized using a random distribution. This offers the advantage of introducing fresh nuances for the task at hand.
Initialization from Vocabulary: A more grounded approach is to initialize these embeddings based on existing vocabulary embeddings. This involves picking embeddings from the GPT’s original vocabulary, ensuring a correlation with previously learned contexts. By providing a string of words in the model’s configuration, the system can tokenize this string and adjust (tile or truncate) to match the total_virtual_tokens. It’s a way of bootstrapping the soft prompts using knowledge the model already possesses.
Model Configuration
No matter the initialization method, it’s crucial to note that the original vocabulary embeddings remain unchanged during prompt tuning. The model is essentially being guided by these virtual token embeddings without altering its foundational knowledge.
P-Tuning:
Prompt Encoder
At the heart of p-tuning is the prompt_encoder, which is an LSTM model. This model predicts the virtual token embeddings, serving as a dynamic guide for the main GPT model.
Initialization and Training
Unlike prompt tuning, the LSTM’s parameters start from a random state. As the training proceeds, while the GPT parameters remain static, the LSTM weights undergo changes. It’s a singular LSTM model, but it generates unique virtual token embeddings tailored to each specific task.
Embedding Insertion
The virtual tokens generated by the LSTM are integrated with the input just like in prompt-tuning, adhering to the template defined by total_virtual_tokens.
Benefits of Integrating Both Methods:
Flexibility: One of the most impressive facets of this architecture is that a single pretrained GPT model can be subjected to both p-tuning and prompt-tuning, albeit not simultaneously for the same task. This provides a spectrum of customization options based on the task’s nature and requirements.Prompt Table: Post p-tuning, the virtual tokens are stored in a prompt_table. This table retains these tokens while discarding the LSTM model, ensuring a compact representation. Tasks can then be fetched based on their name (taskname), and this structure allows for flexibility in the number of virtual tokens used by different tasks.Parameter Efficiency: It’s worth noting the difference in parameter overhead between the two methods. P-tuning, despite its efficiency in using fewer virtual tokens, requires more parameters during training, particularly because of the LSTM’s involvement. The prompt table, however, ensures that only essential parameters (those for the virtual tokens) are retained post-training, achieving parameter efficiency during inference.Shared Parameters in P-tuning: A distinct characteristic of p-tuning is that the LSTM shares parameters across tasks during training. This could offer shared insights between similar tasks but might be less effective if the tasks are highly disparate.
In a nutshell, both prompt tuning and p-tuning are advanced methods that allow for task-specific customization of a GPT model without altering its core parameters. The choice between them hinges on the specifics of the application and the desired balance between parameter efficiency and task specificity.
Flexibility in Setting New Tasks:
The beauty of p-tuning and prompt-tuning lies in its inherent flexibility. Once a model is trained using these methods, it’s not set in stone. Researchers can always revisit the model to add more tasks, ensuring that existing virtual prompts remain intact. There’s also a degree of freedom in selecting the number of total_virtual_tokens for different sessions, provided tasks that are tuned simultaneously utilize the same count.
Bridging Prompt Tuning with NeMo Dataset Preprocessing and Formatting:
Given our understanding of prompt tuning and p-tuning, an essential aspect to streamline the process is efficient dataset preprocessing, prompt formatting, and configuration for model training.
NVIDIA NeMo, a state-of-the-art conversational AI toolkit, simplifies these stages by offering a structured approach for all aforementioned steps. Let’s delve into NeMo’s dataset preprocessing and prompt formatting, and see how it elegantly aligns with our previously discussed concepts.
NeMo Dataset Preprocessing:
- Data Structure: NeMo accepts datasets in the form of lists containing json/dictionary objects. These objects can either be directly part of a list or they can be housed in separate .jsonl files which can then be collated.
- Data Fields: Two essential fields in these json objects are:
- taskname: An identifier string representing the specific task.
- Additional fields representing different components of the text prompt, like “context”, “question”, “answer”, etc.
Example:
[
{"taskname": "squad", "context": [CONTEXT_PARAGRAPH_TEXT1], "question": [QUESTION_TEXT1], "answer": [ANSWER_TEXT1]},
{"taskname": "intent_and_slot", "utterance": [UTTERANCE_TEXT1], "label": [INTENT_TEXT1][SLOT_TEXT1]},
]Prompt Formatting in NeMo:
- Prompt Template Configuration: For customizing prompts for various tasks, the configuration requires defining task-specific templates. These templates integrate virtual token markers, indicative of where virtual tokens will be positioned.
- Virtual Token Placeholders: Placeholders like <|VIRTUAL_PROMPT_#|>, , , and in the prompt templates are indicative of virtual token positions. Their precise number is determined by the values in virtual_token_splits.
- Variable Field Extraction: NeMo allows dynamic insertion of values from the data json using variable fields, represented as {var}. For example, {sentence1} would pull the value associated with the key “sentence1” from the data json.
- Example of Prompt Formatting:
Given the data JSON…
{"sentence1": "And he said, Mama, I'm home.", "sentence2": "He didn't say a word."}…with configurations set as…
virtual_token_splits = [3, 3, 3]
prompt_template = " Hypothesis: [sentence1], Premise: [sentence2] Answer:"…the processed input becomes:
VVV Hypothesis: And he said, Mama, I'm home. VVV Premise: He didn't say a word. VVV Answer:Practical Deep Dive: P-tuning on the SQuAD Dataset
Objective:
The goal here is to fine-tune a MegatronGPT LLM model to perform question answering, utilizing the SQuAD dataset.
Dataset Overview:
SQuAD (Stanford Question Answering Dataset) contains questions crafted by crowd workers based on Wikipedia articles. Every question has an answer which is a segment extracted from the text. It’s well-known in the natural language processing community and is often a challenging dataset for QA tasks.
Here’s the code to extract, process, and serialize our dataset into a version W&B Artifact:
run = wandb.init(config=args)
args = run.config
...
download_file("URL_TO_DEV_DATA", str(DATA_DIR))
subprocess.run(["python", f"{DATA_DIR}/preprocessing_script.py", "--data-dir", DATA_DIR])
subset_jsonl(f"{DATA_DIR}/train.jsonl", f"{DATA_DIR}/short_train.jsonl", 2000)
...
data_artifact = wandb.Artifact(name="dataset", type="datasets")
data_artifact.add_dir(DATA_DIR)
run.log_artifact(data_artifact)
run.finish()Data Structuring for Prompt Learning:
- The dataset is arranged in a list of JSON objects.
- Each JSON object contains a mandatory field taskname that identifies the task, which in this case, is “squad”.
- Additional fields like “context”, “question”, and “answer” capture the relevant data.
Example Structure:
[
{"taskname": "squad", "context": [CONTEXT_PARAGRAPH_TEXT1], "question": [QUESTION_TEXT1], "answer": [ANSWER_TEXT1]},
...
]The SQuAD dataset has been divided into three splits: train, validation, and test. Each split has been saved in a .jsonl file format, with each line in the file being a JSON object. A preprocessing script prompt_learning_squad_preprocessing.py generates these splits.
Setting Up Configuration for P-tuning with NeMo:
With the data structured, the next phase involves configuration setup for p-tuning.
1. Model Selection:
- NeMo’s p-tuning leverages a class named MegatronGPTPromptLearningModel.
- This class requires a specific configuration file tailored for prompt learning.
2. Configuration Setup:
- Start with a prompt learning configuration file.
- Adjust this file to match the specific requirements of the SQuAD dataset.
3. Configuring the Dataset:
- The next step is to configure the GPT model to recognize the SQuAD data splits that have been prepared.
- This involves populating specific configuration parameters to guide the model on which data to train, validate, and test on.
Using Weights & Biases Artifacts we are able to flexibly and conveniently serialize configurations, datasets, and relevant processing scripts into one centralized record with automatic version tracking. Updating datasets in an Artifact in one script ensures that the latest version of that data is used with the remainder of our machine learning workflow, be it for training or evaluation.
Training
Setting Task Templates:
Every task has specific requirements. The configuration for the SQuAD task includes:
- taskname: This matches the taskname field in the dataset, acting as an identifier.
- prompt_template: This specifies how to arrange the data fields and where to put the virtual tokens.
- total_virtual_tokens: This indicates the total count of virtual tokens to be inserted.
- virtual_token_splits: Divides the virtual tokens among the <|VIRTUAL_PROMPT_#|> markers. The sum of tokens here should equal total_virtual_tokens.
- truncate_field: This denotes which data field to truncate if the input length exceeds the model’s sequence capacity.
- answer_only_loss: Decides whether to compute loss only on the answer segment. Recommended for longer prompts.
- answer_field: Identifies the data field related to the answer.
In our setup, the SQuAD task has a different number of virtual tokens than some other tasks. This differentiation is crucial as the tasks are being p-tuned at different times, and one can alter the number of tokens across sessions.
Example Task Template:
config.model.task_templates = [
{
"taskname": "squad",
"prompt_template": "<|VIRTUAL_PROMPT_0|> Context: {context}\n\nQuestion: {question}\n\nAnswer:{answer}",
"total_virtual_tokens": 15,
"virtual_token_splits": [15],
"truncate_field": "context",
"answer_only_loss": True,
"answer_field": "answer",
},
]Incremental Learning with New Tasks:
A distinct feature of p-tuning is the ability to incrementally train models on new tasks without affecting previously trained prompts. The configuration helps to distinguish between:
- new_tasks: The tasks that the model hasn’t been trained on.
- existing_tasks: The tasks that the model already knows about.
config.model.existing_tasks = []
config.model.new_tasks = ["squad"]Model Selection and Preparation:
The GPT model to be utilized for prompt learning is chosen based on size and training goals. Larger models (like those with 5 billion parameters) tend to perform better in prompt learning
This model is procured from NVIDIA’s NGC. If the goal was to use the GPT class directly, one could instantiate it and download. However, for this tutorial’s purpose, only the .nemo file is necessary.
gpt_file_path = "{MODEL}.nemo"
config.model.language_model_path = gpt_file_pathExperiment Tracking:
Keeping track of experiments and their respective metrics and configurations is essential for analyzing and comparing different model versions and setups. This experiment tracking allows for better understanding and evaluation of the models, helping in the selection of the best performing model.
NeMo comes packaged with a wandb logger to handle this task:
# Assigning the name for the configuration from the provided arguments.
config.name = args.name
# Setting the flag to decide whether to resume the experiment if it already exists.
config.exp_manager.resume_if_exists = args.resume_if_exists
# Enabling or disabling the creation of Weights and Biases (wandb) logger.
config.exp_manager.create_wandb_logger = args.create_wandb_logger
# Specifying the project name for the wandb logger.
config.exp_manager.wandb_logger_kwargs.project = args.project
# Deciding whether to log the model with wandb or not.
config.exp_manager.wandb_logger_kwargs.log_model = args.log_model
# Setting the flag to decide whether to save the NeMo model at the end of training.
config.exp_manager.checkpoint_callback_params.save_nemo_on_train_end = (
args.save_nemo_on_train_end
)
# Setting the flag to decide whether to always save the NeMo model.
config.exp_manager.checkpoint_callback_params.always_save_nemo = (
args.always_save_nemo
)
# Setting the flag to decide whether to save only the best model during the training.
config.exp_manager.checkpoint_callback_params.save_best_model = args.save_best_modelRunning Training:
After setting relevant configurations we can retrieve our dataset:
# Retrieve latest SQUAD data from W&B
squad_art_path = run.use_artifact("squad:latest", type="datasets").download()
SQUAD_DIR = os.path.join(squad_art_path, "data", "SQuAD")
...
config.model.data.train_ds = [f"{SQUAD_DIR}/squad_short_train.jsonl"]
config.model.data.validation_ds = [f"{SQUAD_DIR}/squad_short_val.jsonl"]And then run training
# Data Distribution
strategy = NLPDDPStrategy(
find_unused_parameters=False, no_ddp_communication_hook=True
)
#DDP over all GPUs
plugins = [TorchElasticEnvironment()]
# Pytorch Lightning Trainer
trainer = pl.Trainer(plugins=plugins, strategy=strategy, **config.trainer)
# Init the experiment manager and view the exp_dir
exp_dir = exp_manager(trainer, config.get("exp_manager", None))
exp_dir = str(exp_dir)
model = MegatronGPTPromptLearningModel(cfg=config.model, trainer=trainer)
trainer.fit(model)

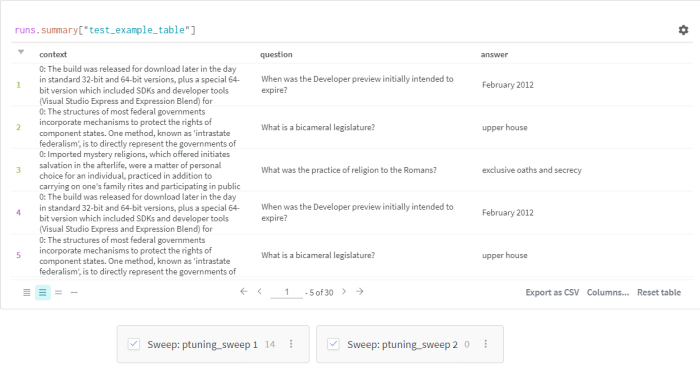
We can now investigate our LLM generations via W&B Prompts Tables
response = model.generate(inputs=test_examples, length_params=None)
prediction_table = wandb.Table(
columns=["prediction", "context", "question", "answer"]
)
for sent in response["sentences"]:
context, question, answer = split_text(sent.strip().replace("\n", " "))
prediction_table.add_data(sent, context, question, answer)Note: we save our final checkpoints after training. After evaluation we can select and place our best model in our Model Registry.
We already autolog all checkpoints with the built in logger!
trained_model_chkpt = Path(exp_dir, "checkpoints", config.model.nemo_path)
final_chkpt = wandb.Artifact(name="final_model_checkpoints", type="model")
final_chkpt.add_file(trained_model_chkpt)
...
final_chkpt.link(LINK_TO_MODEL_NAMESPACE, aliases=["latest", "candidate"])
We can infer using this checkpoint
model_art = run.use_artifact(model_art_link)
final_chkpt_path = model_art.download()
tuned_model_path = os.path.join(final_chkpt_path, "NeMo_Megatron_PTuning.nemo")
gpt_model_file = os.path.join(
final_chkpt_path, "nemo_assets", "{MODEL}.nemo"
)
cfg.virtual_prompt_model_file = tuned_model_path
cfg.model = {
"language_model_path": gpt_model_file,
"virtual_prompt_style": VirtualPromptStyle.P_TUNING.value,
}
cfg.gpt_model_file = gpt_model_file
model = MegatronGPTPromptLearningModel.restore_from(
restore_path=cfg.gpt_model_file,
trainer=trainer,
...
)
Automating Experiment Management with NeMo, Launch, and Google Vertex
Using W&B Launch to Manage NVIDIA NeMo Model Experiments
Running experiments for machine learning models, such as NVIDIA NeMo models, can be resource-intensive, especially when scaling up to large datasets or more sophisticated architectures. W&B Launch simplifies the complexities associated with managing such machine learning experiments. For our Megatron Finetuning, which required extensive computational resources and multiple iterations, W&B Launch provided a unified, efficient, and scalable solution. By combining the power of NVIDIA’s NeMo toolkit with W&B’s experiment management capabilities, researchers and practitioners can focus more on model development and less on infrastructural challenges.
What is and Why Use W&B Launch?
Scalability: With W&B Launch, you can easily scale your training runs from your local machine to a more powerful compute resource like Google Vertex AI, Kubernetes, etc., without major changes to your workflow. Efficiency: By using a queue system, you can prioritize and run your experiments in an organized manner, ensuring that resources are used optimally. Versatility: Regardless of where you want your model to run (e.g., on-premise, cloud, or even on edge devices), you can manage it all from a single platform. Reproducibility: The structured way of tracking experiments, including code, hyperparameters, and output metrics, ensures reproducibility, which is crucial in scientific experiments.
How to Use W&B Launch for NVIDIA NeMo Models
1. Create a Launch Job:
– This was automatically created when running our experiment with our logger.
2. Queue Your Job:
– Through the W&B dashboard, navigate to the job you’ve just created and enqueue it. You can specify the target resource (e.g., GCP Vertex) for the job at this point.
3. Deploy an Agent:
– Deploy a W&B launch agent on the infrastructure of your choice. This agent will be responsible for polling the queue and executing jobs.
4. Monitor and Manage:
– You can view the progress, metrics, and logs of your NeMo experiments in real-time on the W&B dashboard.
5. Iterate:
– Based on the results, you can easily iterate over your experiments, tweak hyperparameters, and requeue them, all managed efficiently through W&B Launch.
In Conclusion
In this detailed exploration, we looked at the essence of prompt-tuning and p-tuning using a library analogy to understand the dynamics of tailoring large language models like MegatronGPT for specific tasks without restructuring their core knowledge.
Emphasizing the efficiency and adaptability of prompt tuning, we showcased how tools like NVIDIA NeMo and Weights and Biases (W&B) streamline this process. While diving into the SQuAD dataset—a robust platform for Question Answering based on Wikipedia articles—we provided insights on data structuring, integrity, and configuration for prompt learning.
We highlighted p-tuning’s prowess for incremental learning, ensuring retention of prior knowledge while embarking on new tasks. Furthermore, the integration of W&B not only facilitates meticulous experiment tracking but also, with features like W&B’s Launch, offers seamless management of NVIDIA NeMo model experiments. This synthesis of NeMo and W&B illuminates the future of efficient, scalable, and precise ML experimentation, emphasizing the strategic avoidance of the complexities associated with traditional fine-tuning.
About Weights & Biases:
Weights & Biases is the leading developer-first MLOps platform that provides enterprise-grade, end-to-end MLOps workflow to accelerate ML activities. Used by over 700,000 ML practitioners including teams at OpenAI, Toyota, Microsoft, and hundreds more, Weights & Biases is part of the new standard of best practices for machine learning.
About NVIDIA NeMo:
NVIDIA NeMo is an all-encompassing conversational AI toolkit. Tailored for researchers focusing on fields like ASR, TTS, LLMs, and NLP, its primary intent is to promote the reuse of prior works, encompassing both code and pretrained models, to foster the creation of advanced conversational AI models. NeMo’s unique advantage is its seamless integration with Lightning, facilitating scalable training across a myriad of GPUs. Impressively, with NeMo’s Megatron LLM models, training can be scaled up to a staggering 1 trillion parameters by harnessing the power of tensor and pipeline model parallelism. Furthermore, these models, post-optimization, can be deployed efficiently using NVIDIA Riva for real-world applications.
To connect this back, while prompt tuning and p-tuning offer a mechanism to adapt GPT models for specific tasks without overhauling the foundational knowledge, tools like NeMo ensure that researchers have an efficient means to preprocess data, format prompts, and then use these to prepare up-to-date model with appropriate knowledge and task specificity. This synergy between ensures rapid experimentation and more effective outcomes.



.png)