
.png)
In September 2023 we conducted a survey with the MLOps Community on evaluating LLM systems
In September 2023 we conducted a survey with the MLOps Community on evaluating LLM systems. More than 115 people participated. All of the response data is free for anyone to look at and examine.
We encourage you to dig into the responses to come to your own conclusions. This post is a summary of some of the key insights.
We are currently conducting a new evaluation survey. Take five minutes and fill it out.
Participants
The survey shows that 118 people filled out the form. The majority of these respondents were C-suite executives, ML engineers, and data scientists. 31% work at companies with more than 1000 employees while 29% work at small startups with 2-9 employees. 68% had job titles with CxOs, tech leads, Sr. or head of.
The specific industries of the participants’ companies range from finance, developer tooling, agriculture tech, and consulting to e-commerce.
Budget
Yes.
There is budget.
No surprise here.
A combined 81% of the respondents noted they had allocated budget to exploring LLMs. 45% of respondents said they are using existing budget. Have traditional teams pivoted focus? ML teams aren’t only tasked with doing “classical” ML but need to also explore LLMs.
What’s the takeaway from this?
The hype is real.
A huge chunk of respondents have new budget for this. VC money is pouring into the AI space with over 20 billion invested into generative AI companies in 2023. Public companies need to answer their shareholders’ naive questions about their “AI Strategy”.
Model Size
There seems to be a dichotomy forming that is pretty clear in the responses.
Participants are either using smaller open-source models or OpenAI. Other 3rd party model provider APIs were less common.
Let’s unpack that for a second.
Smaller models are easier to deploy, faster, and cheaper. For the GPU poor they work. Rapid advancements are being made in the open-source community wrt model sizes. Each week resource requirements go down. Llama.cpp and Ggml are examples of projects respondents highlighted using that speak to this momentum.
But it’s a trade-off.
Smaller models are less accurate and perform worse than an open AI model. Performance and accuracy seem to be two things that do not coexist at the moment.
You can ONLY have two out of three – fast, cheap, accurate.
89% of respondents noted that accuracy was important. This makes it the most out of any other metric. Hallucinations and truthfulness were also top of mind for respondents. It’s clear what is important in the current landscape.
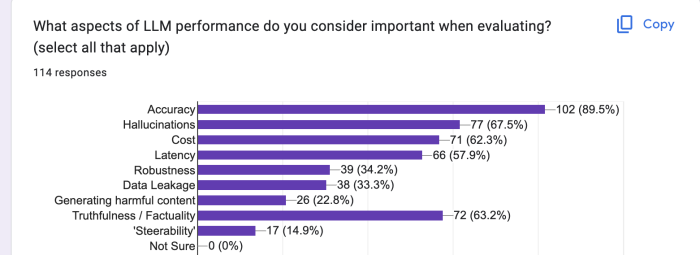
Metrics
The use case determines how performance is evaluated. This survey confirms this assumption. The use case plays just as big of a role as the LLM itself and the metrics used to evaluate it.
The metrics participants say they use reflect that. Classification regression metrics are the most used presumably because it’s the most common use case. Custom offline question-answer pairs where participants manually look at responses are used by a third of respondents.
Another common theme is to use AI to grade the output of the models. A third of respondents noted they are using model-graded metrics for evaluation purposes. This obviously is a much more scalable way to evaluate models.
New techniques for LLMs to evaluate other model’s outputs are coming out frequently. It is no secret that AI tends to prefer other LLMs’ output. New system designs to optimally leverage LLMs evaluation abilities come out every week (more on that below in the challenges section).
Data
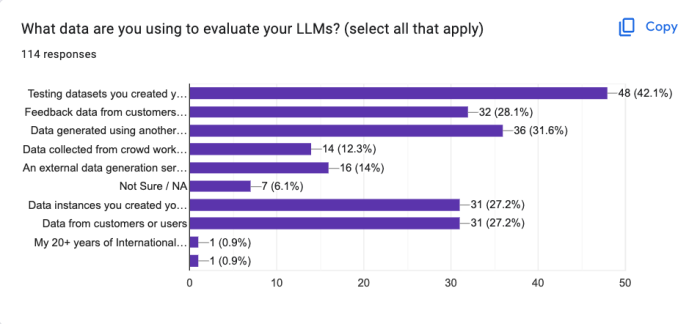
The data sets participants are using for their evaluation sets are not clear. It’s actually all over the place.
The most common eval data comes from humans in some way shape or form. Datasets participants created themselves are the most common. Both feedback from end users and data generated from another LLM is common.
When asked if participants have ground truth labels and if so, how they were generated there was a clear trend in the responses. 72% of ground truth labels were manually labeled by humans.
Sounds expensive.
A significant amount of respondents (35%) mentioned they do not have ground truth. And 20% use another LLM to label ground truth.
Challenges
The challenges people talked about are some of the best gems in the survey.
It is worth going through all of them yourself. They show the most painful aspects of working with LLMs right now. I felt seen when reading some of these responses.
Recurring themes were:
- Hard to measure output quality
- Lack of data
- Hallucinations seem credible
- New field, things move fast
- Lack of consistent guidance
It’s true, things move fast.
Models are constantly changing. How you interact with those models and the secrets of how to get the most out of each model is a moving target. You never know if you have reached the best you can get.
API providers are quick to update models and the same model behind the hood can have drastically different results out of nowhere.
Are participants making progress at the rate they would like?
These responses reiterate not everything is roses and tie-dye when working with LLMs. Uncertainty around regulation and stakeholders’ uneasiness hinders projects velocity to production (on top of all the other challenges).
Real-time evaluation
It seems the majority of respondents are not doing any form of real-time evaluation. When you look at the answers from the question “How are you thinking about real-time evaluation?” the responses are almost memeable.
“That’d be nice” or “I’m not”. Others mentioned real-time eval wasn’t needed and offline evaluation was good enough for their use case.
Those who are doing some form of real-time evaluation cited human feedback and the classic “thumbs up thumbs down” as methods they were using.
Here were some of my other favorite responses on how participants were thinking about evaluating model output in real-time:
- Building dashboards to monitor scores and bulldozing continuous training
- Important, and the only way to actually achieve proper testing
- For now, just flagging and triaging later to be used in the evaluation flow
- Steal from Six Sigma. Figure out baseline error rate, figure out acceptable error rate, and determine sampling rate and methodology.
GPUs
GPU capacity wasn’t a concern for third-party API users. No surprise there.
From an MLOps standpoint, you cannot have a system and only evaluate a small part of it. How do you evaluate each piece of the system?
It seems there are more important things to figure out first. For the majority of respondents, GPU capacity was not something they actively were evaluating.
For the few that were thinking about how to prevision and evaluate GPU resources, their responses ranged from quantizing models all the way to “project capacity forecasting based on GPU performance testing”.
Other Takeaways
This is meant to be a primer of the results for those who do not have time to dig into the data. I encourage you to look it over if you can and extrapolate new insights that I may have missed.
As a reminder, we are doing a new evaluation survey and plan to release a larger report on all the key findings. Much like our last report on using LLMs in production, we will highlight key insights with fun visuals and a no-bullshit tone you can expect from the community.
I have partnered with some real professionals at yougot.us this time. No more hack jobs. The sky is the limit.
Final Thoughts
Last interesting tidbits before we go:
- 55% of respondents are fine-tuning models.
One request from a participant:
- Please make a simple pipeline for instruction fine-tuning directives and address GPU needs for models bigger than 1b.
Not sure I will be able to make that, but I did put a song on Spotify partly inspired by all this evaluation talk.
Relevant Content
We have been talking about the topic of evaluation over the past year quite a bit in the community. Here are some relevant links if you want to dive deeper:
- Authoring Interactive, Shareable AI Evaluation Reports
- Evaluating LLMs for AI Risk
- Synthetic Data for Robust LLM Application Evaluation
- All About Evaluating LLM Applications
- Evaluating LLM-based Applications
- Building Context-Aware Reasoning Applications with LangChain and LangSmith
- Guardrails for LLMs: A Practical Approach
- Evaluation Panel

.png)
.png)