Source Language models are powerful artificial intelligence algorithms that have the ability to generate human-like text based on the input they receive

Language models are powerful artificial intelligence algorithms that have the ability to generate human-like text based on the input they receive. They are general-purpose neural networks pre-trained on vast amounts of textual data and learn the statistical patterns and relationships within the language. GPT, BERT, and LLaMA are popular language models provided by large language model (LLM) providers like OpenAI, Cohere, and Hugging Face.
These models have numerous applications across various domains and industries, such as text generation, chatbots, voice assistants, content creation, language translation, sentiment analysis, and personalized recommendations, among others. Language models have diverse applications and continue to be developed and refined, opening up new possibilities.
Importance of vectors in language model applications
Context plays a vital role in human conversations, facilitating smooth communication and understanding across various aspects of life.
Language models leverage contextual information by encoding conversations into numerical representations called vectors, capturing meaning and semantic relationships. These vectors enable models to grasp the context in which conversations occur, whether it involves specific cultural expressions, ongoing discussions, or other contextual cues.
In ML and AI, they are important for the following reasons:
Contextual understanding in conversational AI: By capturing the meaning and relationships of words within an ongoing dialogue, chatbots, and virtual assistants can generate coherent and contextually appropriate responses, improving the quality of interactions.
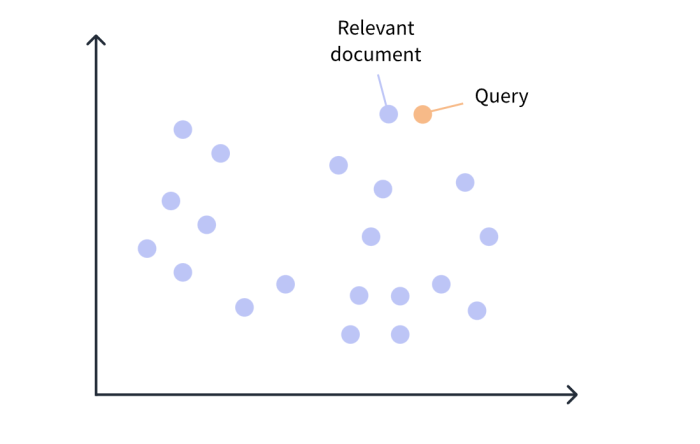
Efficient search and recommendations: Vectors facilitate contextual search and recommendations by capturing the context of user queries and preferences. They enable search engines and recommendation systems to retrieve relevant and contextually appropriate results, improving the accuracy and relevance of suggestions.
Semantic similarity: NLP vectors measure semantic similarity between words and phrases, enabling tasks such as query expansion, clustering, and information retrieval.
They help identify related concepts and improve the accuracy of language models in understanding and generating text.
Transfer Learning: NLP vectors support transfer learning, where pre-trained language models provide a foundation for fine-tuning specific tasks or domains. The vectors capture the knowledge and patterns learned from large-scale training data, allowing models to generalize and adapt to new tasks with smaller datasets, enhancing their performance.
This article will introduce and help you understand vector databases and how to evaluate them in production.
The Role of Vector Databases in Language Model Applications
Vector databases are specialized storage systems designed to store and efficiently retrieve vector representations, such as word embeddings or numerical representations of textual data. They serve as repositories where vectors associated with words or phrases are stored, allowing for fast lookup and comparison operations based on similarity metrics.
Vector databases enable efficient handling of large-scale vector spaces, optimizing storage, retrieval, and comparison operations.

Key features and capabilities of vector databases
Databases serve the purpose of storing both structured and unstructured data. While relational and document databases are commonly used for structured data like personal information and financial data, etc., they may not be ideal for ML/AI applications that involve unstructured data such as images, text, videos, and audio due to their high dimensionality and size.
Traditional databases can introduce delays in information retrieval, making them less suitable for NLP-focused AI applications. In contrast, vector databases offer a more effective solution for storing and retrieving unstructured data. They provide various capabilities to handle unstructured data and empower AI applications efficiently.
Here are some of the things vector databases enable you to do:
Efficient retrieval
Vector databases offer fast and efficient retrieval of vector representations based on queries or similarity measures, allowing language models to access vector embeddings quickly.
Indexing and search
They provide indexing and search capabilities, enabling efficient lookup and retrieval of vectors based on specific criteria, such as similarity search, nearest neighbor search, or range queries.
Scalability
Vector databases are designed to handle large-scale vector spaces, efficiently storing and retrieving millions or even billions of vectors.
Similarity measurement
They offer functionalities to measure the similarity or distance between vectors, facilitating tasks such as semantic similarity comparisons, clustering, and recommendation systems.
High-dimensional vector support
Vector databases can handle high-dimensional vectors, often used in language models, allowing for the storage and retrieval of complex representations.
Vector databases can store geospatial data, text, features, user profiles, and hashes as metadata associated with the vectors. Although the primary focus of vector databases is on storing and querying vector data rather than cryptographic hashes.
How vector databases enhance language model applications
Vector databases offer significant enhancements to language model applications, impacting performance-related metrics like:
- semantic caching,
- long-term memory,
- architecture,
- and overall performance.
Semantic Caching
Vector databases excel at capturing semantic relationships and similarities between textual data. They facilitate efficient semantic caching by storing vector representations of documents, words, or phrases. Once a query is executed and its results are obtained, the corresponding vectors and their semantic context can be cached.
Subsequent similar queries can leverage this semantic cache to expedite retrieval, leading to faster response times and improved query performance.
Long-Term Memory
Language models often benefit from long-term memory, enabling them to retain information and context over multiple interactions or queries. Vector databases provide an architecture that allows for the storage and retrieval of vectors associated with historical interactions or training data.
This enables language models to access and reference previous contexts, generating more coherent and contextually relevant responses.
Architecture
Vector databases offer a scalable and distributed architecture that can handle large-scale language model applications. They allow for parallel processing and distributed storage, enabling you to work efficiently with massive volumes of textual data.
This architecture supports high-speed retrieval and processing of vector representations, facilitating real-time or near-real-time interactions with language models.
Performance:
Vector databases contribute to improved performance in language model applications in multiple ways.
Firstly, using vector representations reduces the computational complexity of similarity calculations for faster retrieval of semantically similar documents or phrases. Secondly, the distributed and scalable architecture of vector databases ensures that performance remains consistent even as the dataset scales.
Finally, the efficient indexing and retrieval mechanisms of vector databases enhance the overall responsiveness and speed of language model applications.
When you leverage vector databases for your language model applications, you can achieve enhanced performance, especially in terms of scalability and overall query processing speed. These improvements contribute to more accurate and contextually aware responses, better user experiences, and increased efficiency in language-driven applications.
Understanding the Different Types of Vector Databases
There are different types of vector databases, like distributed vector databases, vector databases based on processing (in-memory and GPU-accelerated vector databases), or simple vector search engines. This article focuses on the following:
- Graph-based databases.
- Document-based databases.
- Key-value stores.
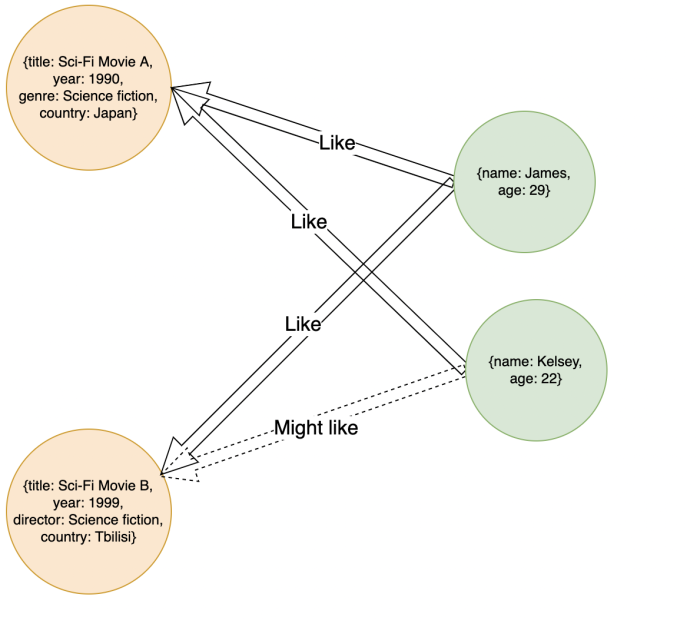
Graph-based databases
Graph-based vector databases leverage graph structures to represent and store vectors. Nodes or edges in the graph are associated with vector representations. You can perform similarity searches and traversal operations using graph algorithms like nearest neighbor search, personalized PageRank, or graph clustering.
While graph databases excel at capturing relationships, some relationships can lack inherent meaning or relevance in certain contexts. The relationships established between nodes in this type of database can be based on arbitrary connections or associations. This can mean that not all relationships in a graph database necessarily have a meaningful interpretation.
It is left for you to structure and design properly to maintain functional relationships. This makes it easier to query the database for better insights into those relationships.

Use Cases:
Graph-based databases are well-suited for recommendation systems, graph-based information retrieval, network mapping, and fraud detection.
Document-based databases
This type of database stores vector representations of the corresponding documents or texts, enabling efficient indexing and retrieval based on document-level semantics
You can leverage common techniques like bag-of-words (TF-IDF), latent dirichlet allocation (LDA), n-gram, skip-thought vectors, and paragraph vectors (Doc2Vec) to generate document embeddings.
Once you send the document embeddings to the database, they undergo indexing, where they are organized and stored in a structured manner. This indexing enables efficient retrieval of documents based on similarity or relevance. During indexing, the database optimizes storage and retrieval efficiency to enhance performance.
To enhance the user experience of large language applications, you can design an architecture that leverages the database’s capabilities. When you submit a prompt to find relevant content, it is embedded and used to query the document to identify similar words or connections. This enables the retrieval of relevant information and assists in finding helpful content, such as fixing a specific tool or addressing a challenge.

Use Cases:
Document-based databases find applications in tasks like document similarity search, document clustering, topic modeling, and content recommendation.
Key-value stores
Key-value stores map data with unique keys, which can be numbers or arrays, to look up and retrieve vectors based on keys efficiently. The keys can be identifiers associated with documents, entities, or other data points.
This store is useful in scenarios requiring direct access to specific vectors based on their keys. In terms of structure, they are a non-relational database and extremely flexible. Values stored in this database can range from strings, numbers, binary objects, or JSON documents, depending on the use case.
It prioritizes speed and efficiency. They are optimized for high-performance operations such as fast data insertion, retrieval, and update. Key-value stores often provide low-latency access to data, making them suitable for use cases that require real-time processing and quick response times.

Use Cases:
They can be used in applications like cache systems, approximate nearest neighbor searches, and storing and retrieving word embeddings.
Comparison of vector databases
Stating the obvious here, but understand that your choice of vector databases will depend on your use case. With this in mind, it is a good idea to consider the comparisons and make a choice based on your project to achieve optimal performance. Here are some pros and cons for each type:
Graph-based databases
Pros:
Efficient for graph-based similarity search, can capture complex relationships between embeddings, and is well-suited for recommendation systems and graph analysis tasks.
It allows you to compute multiple dimensions of relationships.
Cons:
There’s an overhead in maintaining the graph structure, which may also require specialized knowledge of graph algorithms and techniques.
There are no standard query languages. It depends on the platform of choice.
Document-based databases
Pros:
Easy integration with document-level semantics, suitable for tasks related to document similarity, clustering, and recommendation.
Once the document is created, minimal maintenance is needed. It might need to be updated from time to time.
Cons:
May not capture fine-grained word-level relationships; limited to document-level operations.
They face limitations in enforcing strict schema consistency, cross-document consistency, and may require manual or application-level checks.
Key-value stores
Pros:
Simple and efficient lookup and retrieval of vectors based on keys, versatile for various applications.
High performance and speed for quick information retrieval.
Cons:
Limited to key-based retrieval and may not provide advanced similarity search capabilities.
Not suited for complex queries and data relationships
Table 1. Shows the advantages and disadvantages of the various vector databases covered
Graph-Based Databases | Document-Based Databases | Key-Value-Based Databases | |
Advantages | 1. Highly effective for complex data relationships and querying. | 1. Flexible schemas allow storing varying structures of documents. | 1. Simplicity and high performance in read/write operations. |
2. Ability to represent and analyze relationships between entities. | 2. Native support for document-oriented data models. | 2. Scalability and high throughput, especially for large datasets. | |
3. It is well-suited for scenarios with interconnected data elements. | 3. Easy integration with popular programming languages and frameworks. | 3. Efficient caching and retrieval of data based on unique keys. | |
Disadvantages | 1. It is complex to implement and manage simple data structures. | 1. Limited support for complex querying, especially across different documents. | 1. Lack of advanced querying capabilities and limited data relationships. |
2. Higher storage and computational requirements for large graphs. | 2. Less suitable for scenarios with highly normalized or relational data. | 2. Limited data manipulation capabilities compared to relational databases. | |
3. Steeper learning curve for developers unfamiliar with graph theory. | 3. Slower performance for complex queries involving multiple documents. | 3. Difficulty in handling complex relationships between data elements. |
Choosing the appropriate type of vector database depends on the specific use case and requirements. Graph-based databases are well-suited for graph-related tasks, document-based databases excel in document-level operations, and key-value stores offer versatility and efficient key-based retrieval.
Evaluating Vector Databases in Production
Careful evaluation of performance metrics can help you make informed decisions on the type of database to utilize that meets your production environment’s specific needs. This empowers your language model application for success. When assessing vector databases for production use, several important factors come into play:
- Latency and throughput: Measure the response time (latency) and the rate of processing queries (throughput) to evaluate the speed and efficiency of vector retrieval operations.
- Scalability and data volume: Assess how well the vector database handles increasing data volumes and concurrent user queries without significant performance degradation or resource utilization.
- Query capabilities: Evaluate the vector database’s ability to perform various query operations, such as exact match, range queries, nearest neighbor search, and similarity search, to ensure it meets the requirements of the language model application.
- Integration with existing infrastructure: Consider the ease of integration and compatibility with existing systems, programming languages, and frameworks used in the production environment.
Benchmarking vector databases
Benchmarking involves designing representative evaluation scenarios and collecting relevant performance metrics to assess their suitability for language model applications. Through systematic benchmarking, you can make informed decisions on the selection and optimization of vector databases of your choice. So, how?
- Designing appropriate evaluation scenarios:
Define representative workloads and use cases that mimic real-world scenarios for the language model application. This includes determining the type and size of the dataset, the nature of queries, and the expected concurrency levels.
- Collecting relevant performance metrics:
Execute the benchmarking scenarios and collect performance metrics such as query latency, throughput, memory usage, CPU utilization, and storage requirements. These metrics should reflect the workload and scalability requirements of the language model application.
Here are two case studies:
Case study 1: Evaluating graph-based databases for recommendation systems
- Compare the latency and throughput of similarity search operations in a graph-based vector database against different data volumes and concurrency levels.
- Assess the scalability of the graph-based database by gradually increasing the dataset size and evaluating its impact on query performance.
- Measure the effectiveness of the database in supporting personalized recommendations based on semantic similarity.
Case study 2: Evaluating document-based databases for text clustering
- Benchmark the document-based vector database’s ability to cluster similar documents based on their vector representations efficiently.
- Assess the scalability of the database by evaluating its performance with increasing document volumes and varying cluster sizes.
- Compare the query capabilities of the document-based database, such as document similarity search and topic-based retrieval, against predefined benchmarks.
These real-world case studies involve setting up appropriate evaluation scenarios, collecting performance metrics, and analyzing the results to determine the suitability and performance of vector databases for specific language model applications.

Best Practices for Vector Database Integration
When integrating vector databases, follow best practices to ensure smooth integration and maximize performance. These may include designing a scalable architecture and data model, optimizing indexing and query strategies, and considering compatibility with existing infrastructure and tools.
Here are some things to consider for your use case:
1. Preparing data for vector database integration
- Clean and preprocess the data to remove noise, inconsistencies, and irrelevant information that can negatively impact vector representations.
- Apply text normalization techniques such as lowercasing, removing punctuation, and handling special characters to ensure consistency in vector representations.
- Determine a strategy for dealing with words not present in the vector database, such as using fallback embeddings or employing techniques like subword tokenization.
2. Choosing the right vector database for specific use cases
- Consider factors like scalability, retrieval speed, memory usage, and support for specialized operations like semantic similarity or approximate nearest neighbor search.
- Research and compare different vector database systems, considering their features, performance, community support, and integration capabilities.
- Ensure that the chosen vector database aligns with the technology stack and integrates with the programming languages and frameworks you use for your application.
3. Optimizing vector database performance
- Explore different indexing techniques offered by the vector database to optimize retrieval efficiencies, such as hierarchical indexing, graph-based indexing, or locality-sensitive hashing (LSH).
- Apply dimensionality reduction techniques like principal component analysis (PCA) or t-SNE to reduce the dimensionality of the vectors while preserving important information, which can enhance performance.
- Fine-tune the parameters of the vector database to balance indexing speed, storage requirements, and retrieval accuracy.
- Utilize batch processing techniques to optimize the insertion or update of vector data into the database, reducing overhead and improving overall performance.
4. Ensuring scalability and reliability
- Configure the vector database to distribute the workload across multiple machines or nodes for scalability and fault tolerance.
- Implement load balancing techniques to evenly distribute queries or requests across multiple instances of the vector database, ensuring optimal performance.
- Set up replication and regular backups of the vector database to ensure data durability, availability, and recovery in case of failures.
5. Monitoring and maintenance of vector databases
- Continuously monitor the performance metrics of the vector database, such as query latency, throughput, and resource utilization, to identify bottlenecks and optimize performance.
- Implement mechanisms to handle data updates or changes, such as reindexing or incremental updates, to keep the vector database fresh with the latest data.
- Perform routine maintenance tasks like database optimization, index rebuilding, and periodic cleaning of unused data to ensure optimal performance and stability.
- Regularly monitor the quality and consistency of the vector representations by evaluating the performance of downstream tasks or using evaluation datasets to identify potential issues and make necessary improvements.
With these best practices, you can effectively integrate vector databases into your pipelines for accurate and efficient retrieval of vector representations and maximize the performance and scalability of your NLP applications.
Conclusion
In conclusion, understanding and evaluating vector databases is crucial for empowering language model applications in production. By considering factors such as latency, scalability, query capabilities, and integration with existing infrastructure, you can make informed decisions regarding selecting and optimizing vector databases.
Additionally, benchmarking these databases and following best practices for integration can further enhance their performance and suitability for LLM applications, unlocking their full potential and driving impactful outcomes in your domain of interest.


.png)
.png)