
This article is written by Nwoke Tochukwu , a Machine Learning Engineer and also an Undergraduate studying mechatronics Engineering
This article is written by Nwoke Tochukwu, a Machine Learning Engineer and also an Undergraduate studying mechatronics Engineering.
I’ve trained my model and need to deploy it!
Developing machine learning solutions comes with many complexities, especially in the deployment phase. In general, developers need to worry about designing the architecture and building the infrastructure, taking care of environments and all necessary dependencies. With tools like Flask Docker, the whole process is much faster; however, it still requires you to have a perfect understanding of the topic. As a result, many AI creators finish with just a trained model since the deployment is time-consuming and costly.
To solve that problem, we have Syndicai. It makes the ML deployment phase easier and faster since it manages your infrastructure. Step-by-step, we’ll go through the ML deployment phase using the Synicai approach of going from model to production ready API.
A Use Case to Get Us Started
Theoretically, we are building a new product for an EduTech company and we need to create a new feature that helps fill in the blank space in sentences. The complete solution needs to be in the form of an API. All we will need to do is deploy our model to Syndicai and integrate that API into our product.
Easy peasy, right? Well, we’re about to find out that shortly.
Prepare a Model for Deployment
The first thing we need is a machine learning model that is already trained. Let’s use RoBERTa masked language modeling model from Hugging Face. It is already pre-trained with weights, and it is one of the most popular models in the hub.
Create a Git Repository
Syndicai Platform requires us to have a git repository with requirements.txt and syndicai.py. Typically, we would start a new project, but we can fork the repository since the model is already on GitHub. You can access it here.
Add Requirements.txt
First, let’s add the requirements.txt file to our repository. It contains all libraries and frameworks required to recreate the model’s environment in the cloud. Have a look at the file below.
numpy==1.19.4
transformers==4.15.0
torch==1.10.2Note that all libraries consist of exact versions!
Add Syndicai.py
Later add syndicai.py, a python script that contains the PythonPredictor class with a __init__ constructor and predict method.
def __init__(self, config):
device = “cuda” if torch.cuda.is_available() else “CPU”
print(f”using device: {device}”)
self.device = device
self.model = RobertaForMaskedLM.from_pretrained(‘roberta-base’,return_dict = True)
self.tokenizer = RobertaTokenizer.from_pretrained(‘roberta-base’)The constructor is the best place to initialize our weights since Syndicai runs it only once when a deployment is created. The predict method is responsible for taking the input, parsing through the model, and sending a response. It is run every time we send a request to a model, so it needs to be fast and lightweight from a technical point of view. For our purposes, it is only tokenizing the input data, extracting the masked tokens, and processing the output using the Hugging Face API.
Predict method has only one required argument (payload), which allows us to access our input data in the form of a dictionary when we send a request with JSON file that looks as follows.
{"text": "My name is Nwoke Tochukwu, I'm a Machine Learning Engineer What skillsets are <mask> to be a software Engineer."}Check the Model Before the Deployment
Check your model locally before deploying and execute the following command: python3 run.py.
It will send JSON data through your model and test whether everything is okay.
import os
import argparse
from transformers import RobertaTokenizer
from syndicai import PythonPredictor
# tokenizer = RobertaTokenizer.from_pretrained('roberta-base')
sample_data = (
"My name is Nwoke Tochukwu, I'm a Machine Learning Engineer "
"What skillsets are <mask> to be a software Engineer."
)
def run(opt):
# Convert image url to JSON string
sample_json = {"text": opt.text}
# Run a model using PythonPredictor from syndicai.py
model = PythonPredictor([])
response = model.predict(sample_json)
# Print a response in the terminal
if opt.response:
print(response)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--text', default=sample_data, type=str, help='URL to a sample input data')
parser.add_argument('--response', default=True, type=bool, help='Print a response in the terminal')
opt = parser.parse_args()
run(opt)It’s Time to Deploy RoBERTa!
It’s finally time to deploy on Syndicai. Connect the git repository to the platform, create a deployment, and run the deployment to validate whether it is working correctly.
Connect the Git Repository to the Platform
In order to connect a git repository, we need to log in to the Syndicai Platform, go to the Models page, and then click the ‘Add New Model’ button. In the pop-up form, paste the following data and then click ‘Add’.
- git repository: https://github.com/Tob-iee/syndicai-tutorial/
- path: my-model/
The path needs to target the syndicai.py & requirements.txt.

Add a new model by connecting a git repository with a path.
After connecting a repository, you will be redirected to the Model Profile.

Model Profile — Connected repository with a path “my-model”
Create a deployment
On the Model Profile page, click the ‘Deploy’ button. We’ll fill out the deployment form with the name and a branch. In general, the deployment is connected to a branch.
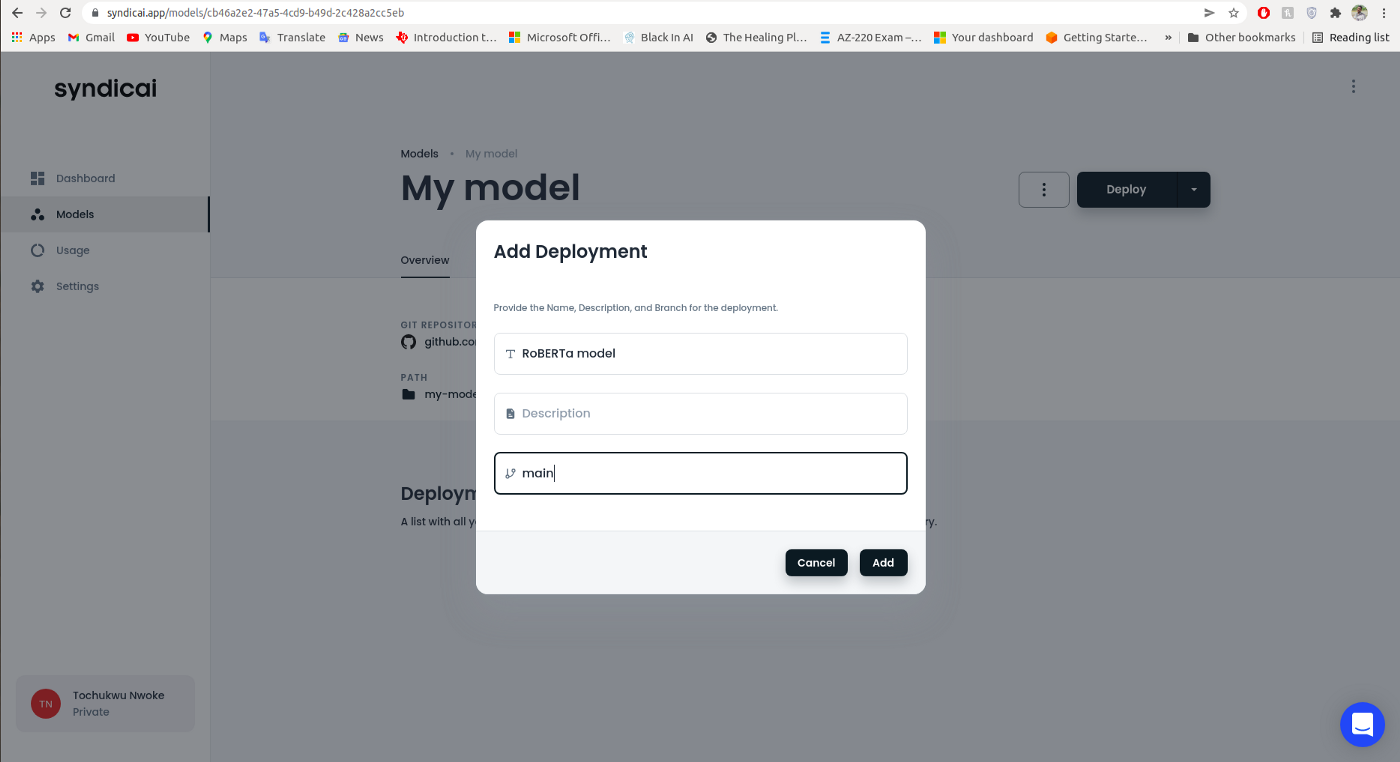
Create a new deployment on the main branch.
Clicking ‘Add’ will redirect us to the Deployment Profile with the new release in the ‘Releases’ tab.
Note: If you click on the recent release e.g. #1 you will see logs from the building and starting process. The building phase covers wrapping a model with the web service and docker container. At the same time, a starting phase covers serving a docker container in the cloud.

Deployment Profile — The release is still in progress…
We’ll need to wait for a couple of minutes to get the running status of the deployment.
Run and Validate the Deployment
When a deployment is running, we can send requests and later integrate in the form REST API with our product.
It is not necessary to go to the terminal and paste a complete request to test the deployment since we can quickly test the running deployment on the platform.
Go to the ‘Overview’ tab in the Deployment Profile and scroll down to ‘Validate & Integrate’ section. Click on the pencil icon in the dark box for sample data. Paste the following input code.

Deployment Profile — Add input data in the form of JSON in the Validate & Integrate section.
Click ‘Update to Save’ and then click ‘Send a Request’ to test the deployment. We should get the following response.

Deployment Profile — Response from the deployment
Remember that your deployment needs to have a running status to work!
Conclusion
Congratulations! We were able to deploy a scalable machine learning model seamlessly without worrying about the underlying infrastructure that generally requires specialized knowledge in DevOps and Software Engineering. Syndicai helped us go from a trained model to a scalable API in minutes. And the beautiful thing is that you don’t have to worry about maintenance.
(P.S. Now that you’ve gone through the whole article, you can just fork the ready-made code, and jump straight to the deployment section.)



.png)