
This article is written by Breno Costa ( The original post can be found here )
This article is written by Breno Costa ( The original post can be found here ).
Organizational Structure
On Team Topologies
Redesigning our Teams
Interaction Between Teams
Internal Platform Teams
Machine Learning Platform
Early Challenges
Product Thinking
User Interviews
Proto-Personas
User Story Map
Prioritization
Agile Execution
- Key Takeaways
Neoway is a Brazilian company that generates intelligence for decision-making and productivity for the processes of marketing, compliance, fraud prevention, legal analysis, and credit management. Since its foundation, the company has invested in a data platform for collection, ingestion, treatment, and presentation that can be used to create products and services for different use cases.
In the last five years, data science and machine learning have emerged to bring more intelligence in solving customer problems and currently play a key role in the solutions that make up the portfolio. Models, indicators, intelligent journeys are examples of data science-powered applications delivered on our web application or via APIs.
The company’s growth brought new challenges to maintain a good communication structure among teams and fast business value delivery to the customers.
Organizational Structure
For a long time, the company was organized by functional areas like platform, data engineering, data science, application, product. This kind of organization caused functional silos that led to problems such as lack of systemic thinking, and hard dependency management during software development.
For instance, the data science team struggled to get historical data in the proper format for the modeling tasks. The team also had difficulties deploying model predictions integrated with the company’s architecture. Both tasks had dependencies with internal teams and the services were not provided properly.
That organizational structure resulted in inefficiency to deliver business value to our customers. In early 2020, the company was redesigned into cross-functional teams focused on business domains capable of delivering end-to-end solutions and accelerating software delivery.
On Team Topologies
The Team Topologies book is one of the theoretical references used to redesign the teams at Neoway. It brings new ideas around effective team structure for enterprise software delivery.
The book reinforces the importance of Conway’s law for effective team organization. That theory states that “organizations which design systems are constrained to produce designs which are copies of the communication structures of these organizations”.
The speed of delivery is heavily affected by the organization’s design and the dependencies among its teams. A fast flow of execution requires restricting team communication as much as possible.
The book authors propose to apply a kind of reverse engineering of Conway’s law by designing teams to match the desired architecture! This is team-first thinking. It suggests a business-oriented team design for fast flow based on concepts such as cognitive load, fundamental team types, and interaction modes.
Redesigning our Teams
The organizational structure was changed by choosing business domains to focus on and creating teams to maximize the software delivery to our customers on those domains. The functional teams were changed to cross-functional units of work named cells. They are small units of delivery that work collaboratively.
The stream-aligned and platform are the most fundamental team types in our company. Stream-aligned teams have a continuous flow of work aligned to a business domain. Platform teams provide internal services to reduce the complexity for the stream-aligned teams during software development and delivery.
The image below presents a very summarized view of some cells with which our machine learning platform team interacts the most.

The product and service cells are responsible for delivering value directly to the end customers. They need to be empowered to build and deliver customer value as quickly and independently as possible. Those cells are created to better serve the business domain requirements.
On the other hand, the platform cells have two responsibilities. The first one is to simplify the use of complex technologies that require a high level of specialization, such as Kubernetes, Spark clusters, distributed systems, data lake, streaming platform, IAM, security, data warehouses, search engines… The list goes on.
The second responsibility is to prevent business cells from building multiple solutions for solved problems across the company. When a problem that is common for several teams pop up, the platform cells act to create a single solution that solves the problem more efficiently thinking in the long term.
Interaction Between Teams
The types of interaction can vary according to the maturity of teams and the maturity of solutions provided by them. We’ve seen the three types of communication mentioned in the Team Topologies book happen frequently.
Collaboration is when teams work together on a part of the system.
For example, when a product team needs a software component not provided by the platform. If the platform team has expertise in the technology and can designate a member to work with the product team to help build the solution, both teams can collaborate on this new solution.
The platform team enables a business delivery, enforces good software engineering practices that will sustain the solution in the long term, and may even provide this component via the platform in the future.
Facilitating is when a team acts as a mentor on a specific topic to help another team.
This happens when a team needs help on a specific topic (business or technology) from another one. Both will not be working together, but the helper team will invest time with consultancies like explanations and materials.
A platform team that isn’t very mature or doesn’t have a good documentation, will likely be involved in a lot of mentoring, helping people, and answering questions. Likewise, the same can happen with teams with junior members using our solutions.
X-as-a-service is when a team provides and another team consumes something as a service.
A team that provides solutions for other internal or external teams must constantly seek to maintain this type of interaction. This is better for both. Users need to obtain access and get started quickly while Providers have less mentoring and support overhead.
To achieve this type of interaction, it is necessary to invest mainly in the usability and documentation of the services. A good developer experience is key!
Internal Platform Teams
Platform teams aim to reduce the cognitive load of stream-aligned teams by providing services used by software developers or data scientists that are generally a combination of internally developed and/or externally acquired features.
A platform team analyzes the internal teams’ requirements, looks for external solutions, and makes them more convenient for developers to use on a daily basis. In this context, one of the main characteristics of a good platform is the ease of use and services should be offered in self-service mode with well-written documentation and good support for developers.
Suppose a data scientist with a background in statistics, economics, or physics was hired to create models that bring a high business return to the company. Their scope of work should not include knowledge of details on how to provision infrastructure for deploying models. The platform team should act by solving the inherent complexities and providing a simplified user experience.
The discussion about the importance of platform teams is not something new, but the decision to create it must be considered according to each context. The decision to create an in-house platform team should be a balance between the long-term efficiency and quality benefits versus the financial costs involved in building and evolving it.
Neoway has in its DNA the strengthening of the platform teams, considering the high gains obtained in the creation of different solutions that generate value to customers.
Machine Learning Platform
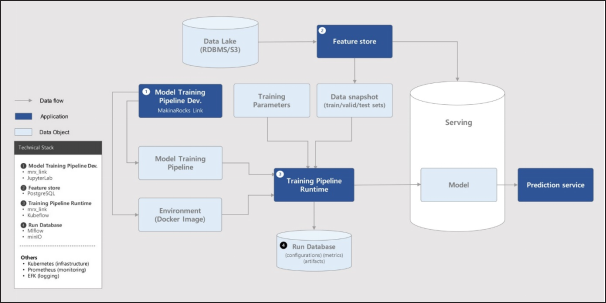
The machine learning platform has components for the major stages of the model delivery lifecycle: data exploration, feature engineering, model development, model deployment, and monitoring.
Our solutions are mainly used by data scientists working in stream-aligned cells who need to do tasks such as provisioning infrastructure for running distributed spark kernels, accessing the data lake in an easy and organized way, creating and running model feature engineering jobs, deploying models into production, ensuring that the models run with quality.
The image below presents a summary of the components of our platform and the integration with other existing components in the company. We’re responsible for providing the blue components in the figure. The yellow and green components are provided by the data platform. Our team is both a consumer and contributor to the internal data platform components.
Data pipelines are created to prepare the raw data that is produced by other applications in a structured format to be used by data science tasks. Every dataset schema is registered and it’s available to users in an organized way for easy discovery and reading.
The Feature Store facilitates the creation and consumption of features used in data science models. It maintains consistency between development and production by using the same feature code in both environments. It encourages the reusability of features across projects and teams. We’ve published an entire blog post on our Feature Store.
The Development Environment enables data scientists to provision the infrastructure of distributed spark clusters with a set of tools installed and configured in an easy way. The users can do any kind of data science tasks like data exploration, feature engineering, model training at scale!
Model productization templates and tools include a data science template to package the source code. It has batteries included to create python modules, run unit and integration tests on CI pipeline, publish docker images in the registry, write and run dags in Airflow.
Pipeline orchestration is the part responsible for running batch pipelines for model training and scoring. We use Airflow to create the DAGs that run periodically, but we use the concept of DAG as a configuration. The data scientist does not need to write complex operators. Just create a file and fill in some configuration parameters. Then just play and run the model to test and if everything is working, the model goes into production.
Model APIs can be used to serve models. They are used in some very specific use cases. Binary artifacts from the models created in the productization step are loaded during initialization and used for making predictions by key. This type of strategy is mostly used by the professional services team according to the clients’ needs. We also have on-demand pipelines where training and prediction pipelines are triggered by the users.
Early Challenges
In the beginning, we had three main challenges to overcome as a machine learning platform team.
Integration with existing solutions in the company: we needed to improve integration with different services of the company provided mainly by the other platform teams.
At that time, teams were not thinking of providing their services for the other internal teams, so the user experience was not good and documentation was not sufficient for understanding how to configure and use those services without the support of other people.
Developer experience of our software components: when we worked on the data science team, there were some projects developed for data preparation, feature engineering, model deployment, etc.
The projects were not developed taking into account aspects such as user experience and a systemic view of the components. The result over time was a bad experience and low user adoption of some components.
MLOPs challenge: we were facing some problems at that time with the models running in production. How to make good governance of features and models? How to deploy models in an efficient way? Many open questions to be answered.
A dedicated team with mixed skills in software engineering, infrastructure, and machine learning could stay focused on how to propose solutions to the main problems brought up by data scientists. While data scientists are more focused on business and statistical skills.
Product Thinking
The first decision was how to approach the challenges above mentioned at that moment.
A technical team may be tempted to solve the problems only from a technical perspective by considering aspects such as scalability, reliability, and maintainability. Those things are important, but the platform solutions can’t fail at a crucial point: user adoption.
In the blog post Mind the platform execution gap, the authors have suggested prioritizing developer experience, and it’s one of the aspects to mind the platform execution gap. The reason is simple: a product that no one uses is not a successful product, no matter its technical merits.
Our team decided to approach the platform with product thinking. We decided to focus on the user needs and experience, but deliver solutions with technical excellence.
From the beginning, we interviewed the users, tried to understand their journey, and listened to their pain points. It’s necessary to see any user perspective on the platform components being developed. An advantage of internal products is that we have closer contact with users through the company’s communication channels. User empathy is the key!
The next sections present some tools we use to improve our understanding of the machine learning platform users.
User Interviews
Our main mission in this stage was to create a connection with people and hear what they had to say about the tools available at that time. Our interview form had three basic questions:
- How do you currently do your data science-related tasks?
- What are your current difficulties?
- What are your suggestions for improvement?
These basic questions can generate so much insight and backlog for the team!
We talked in some user interviews about the features framework, our first set of tools for feature engineering. We found that the user experience was terrible, and that was the main reason why our feature creation tool stopped being used. Those insights helped us a lot on the development of our feature store solution.
Proto-Personas
We used a simple description of proto-personas to describe who are the current and future users of our platform. The image below presents a brief description of some characteristics to clarify it.
Proto-personas give an insight into the characteristics of users, which guide the team to make good decisions in an empathetic way during the software design and development.
User Story Map
The user interviews generated user stories to describe the user needs in a structured way. We used a user story map for creating the entire view of the data science lifecycle.
User story map defines 3 types of actions:
- activities that represent the high-level tasks that users aim to complete in the product;
- tasks that represent the steps in a sequential order to achieve the activity and;
- stories that provide a more detailed level of user needs.
The image below shows an example of our initial user story map.
One of the benefits after making a user story map is to have a systematic understanding of the user journey in a single page.
Prioritization
After talking and understanding the user needs, the team tried to understand the most urgent priorities to improve the users’ workflow and the effort required to deliver them.
Since we’re starting many projects, it was virtually impossible to make reasonable estimates for any user story. The team could not yet learn from its own track record. In this scenario, senior engineers can help to provide an effort estimation at a macro level.
The next step was to group user stories into development epics to solve specific problems (model deployment, feature engineering, etc.). The prioritization matrix was used as a natural framework to help the decision-making on what’s the most important epics to be developed comparing effort vs value.
Another important aspect of prioritization is considering the company’s objectives in the medium and long term. Strategic and tactical managers can help with more clarity about that. After getting input from users and stakeholders, we created OKRs to provide a way to measure our achievements. An OKR can be something like this: “reduce time to put models into production from X to Y” and the development epics must be related with one OKR.
Agile Execution
Agile execution is essential to reduce errors during software development. When we are going to develop some software components for users, we create prototypes to show to a group of users before the development itself. This allows improving before even starting! Software delivery is broken into small parts whenever possible. We generate more value, get feedback and learn from every interaction.
We decided to use scrum as a framework for developing. Our sprint backlog is composed of development epics previously planned on OKRs, operation, and support tasks. It’s common to have some problem someone faced in the previous week and we need to fix it in the new sprint, or someone needing support to deliver some project.
After starting the sprint, we have daily meetings with the entire team to assess progress and resolve any blocks that occurred. This meeting is important to keep everyone’s commitment to what was agreed. Seeing the progress of the tasks on the board renews the motivation to stay focused and seeing the lack of progress turns on the alert for any problems that might be happening.
Our software engineering culture is mature. Every piece of software needs to be reviewed by team members and only can be merged after being accepted by at least one person. Automated tests, documentation, changelog are very important for us, and you use Gitlab for automating CI/CD pipelines. The tasks are done during a biweekly sprint, and we finish with a sprint review and retrospective.
Key Takeaways
During the journey of creating and evolving the machine learning platform at Neoway, we’ve faced a lot of challenges but it has been an awesome learning experience for the team. Some takeaways during this time:
Team design takes an influence on the company’s software architecture and fast flow.
- Delimiting responsibilities brings more clarity to teams and helps dependency resolution.
- Our organizational structure changed for the better, team scopes are more clear and communication between teams is designed for fast flow.
- Don’t design teams too small, try to optimize for autonomy, and set communication types when teams need to work together.
- X-as-a-service communication type needs good services and documentation.
Approaching a machine learning platform with product thinking helps to understand the users and generate more value as a lean team
- Understanding your users is the most important thing you have to do. Do things that don’t scale!
- Involve users from the beginning, show them prototypes, let them use the product, get feedback and improve from there. Don’t involve everyone, prefer more mature and curious users with an early adopter profile.
- A small team needs to optimize for fast and small deliveries.
Internal teams trust internal platform services if they deliver value, are easy to use, and are reliable.
- You will need the understanding of your users when the services present any problem. Don’t let your users down. Provide good support and you will gain their trust.
- Use every interaction with your users to get feedback and improve the services. Payment comes in the long term.
Special thanks to my colleagues working on the Machine Learning platform team Manoel Vilela, Matheus Frata, Victor Gabriel, to the current management team Leandro Leão, Gabriella Xavier, Matheus Vill, and to the people who were part of the team in the past Yuri Vendruscolo, André Bittencourt.


.png)
.png)