

This post was written by Ankit Aggarwal and Vinay Anantharaman at Aurora Innovation

This post was written by Ankit Aggarwal and Vinay Anantharaman at Aurora Innovation. Machine learning is the backbone of autonomous vehicle development. Learn how Aurora’s engineering team designed and implemented a centralized ML orchestration layer that allows it to iterate and ship ideas much more quickly. It originally appeared on the Aurora blog here.
Machine learning (ML) models form the backbone of autonomous vehicle (AV) development. Everything from perception to motion planning is powered in part by the datasets and models developed in a cycle commonly referred to as the “Data Engine.” The Data Engine lifecycle starts with identifying the type of data required to support or improve an AV capability—for example, to detect emergency vehicles, our perception system needs lots of sensor data of emergency vehicles in different situations. This is followed by iteratively mining and labeling the data to turn it into a usable dataset for ML model training. Once a model is trained, it then goes through a number of sub-system and system-level evaluations and those results are fed back to the Data Engine for the next iteration. Our ability to quickly and safely develop, deploy, and continuously improve our self-driving technology is largely dependent upon the efficiency and speed of this lifecycle.
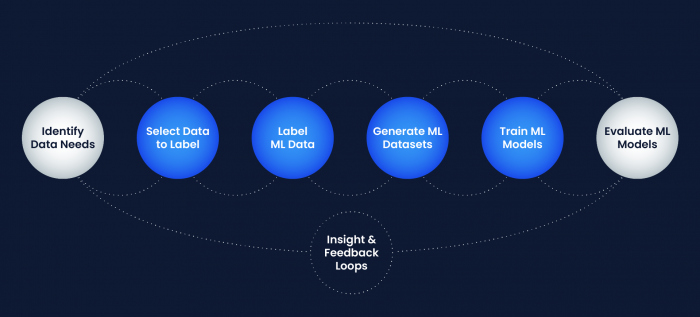
Our ML engineers spend most of their time on the model development workflow within the Data Engine lifecycle. The model development workflow for self-driving technology is different from that of other applications due to a greater number of feedback loops. Our autonomy stack is made up of multiple ML models for perception, motion planning, etc., and changes to a single model can affect the others. This complex set of dependencies with feedback loops that involve external ML tooling, built-in-house tooling, and systems written in C++ and Python makes writing automatable declarative workflows extra challenging.
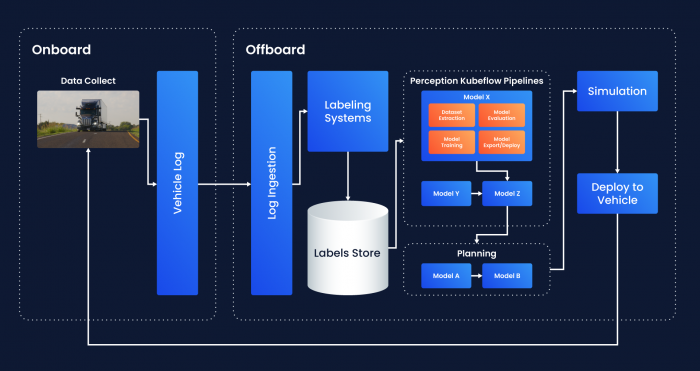
Bottlenecks at any stage can delay the continuous deployment velocity of new data, models, and software to our vehicles, so Aurora’s autonomy team has been working to identify optimization opportunities to increase model development iteration speed and shorten the Data Engine lifecycle, resulting in quicker deployment of improved self-driving models. These efforts have culminated in the development of a centralized ML orchestration layer.
Designing the ML orchestration layer
Through discussions with Aurora’s model developers, we identified the critical pain points slowing down ML experimentation and production—mainly, a lack of automation and cohesion across the model development workflow.
For example, going from new data to a landable production model was a highly manual process and required significant effort. Running model-specific integration tests on code changes was manual and time-consuming. Launching multiple experiments in parallel was labor-intensive due to the lack of experiment tracking and traceability. Additionally, there was no way to integrate multiple subsystems into a single workflow and no unified user interface that allowed developers to visualize and debug the entire lifecycle in one place.
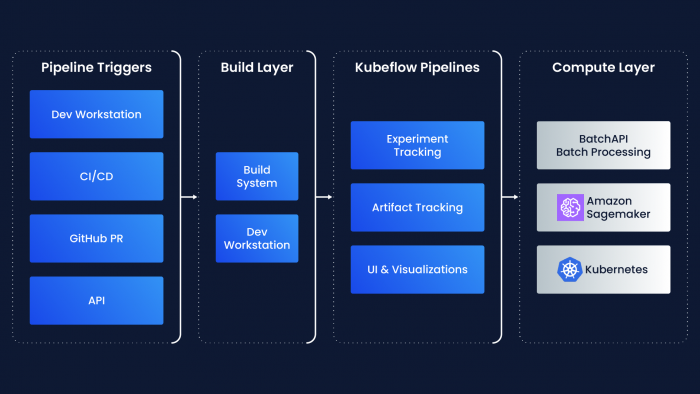
To address these pain points and allow our developers to more effectively navigate through these complex distributed systems and processes without sacrificing development velocity, we decided to design an ML-specific orchestration layer within the ML model development workflow, tailored for AV development. The model development workflow would be split into three layers:
- Build: This layer is where docker images and other build artifacts would be built, supported by Aurora’s Developer Experience team using Buildkite.
- ML orchestration: This layer would orchestrate and track the entire ML workflow lifecycle.
- Compute: This layer would compute various workloads including data processing, training, exporting, and evaluation on external (Sagemaker) and internal systems (Batch API).
Our new ML orchestration layer would include the following improvements:
- Data Engine: Continuous Delivery (CD) of datasets and models within two weeks on availability of new data and feeding the metrics back into the Data Engine for the next iteration.
- Continuous Integration (CI): Automated tests to monitor overall health of end-to-end workflows.
- Integration tests: On-demand tests to validate and verify the changes made to models and workflows.
- Experimentation: Integrated ML tooling and orchestration for the model and dataset development workflows to cut down on manual effort for parallel experimentation and increase iteration velocity.
- Compute stack upgrade: Automated testing for periodic upgrades to the compute stack for CUDA, cuDNN, TensorRT, PyTorch, and other compute libraries.
And it would be designed according to the following principles:
- Automatability: Quickly build new pipelines and pass data between different steps.
- Reusability: Reuse existing declarative components and pipelines between models and teams.
- Scalability: Scale with data, models, and experiments as well as with number of users/developers. Scale different workloads separately (training, data, export, evaluation).
- Security: Streamline roles/policies for each layer to create a small surface area.
- Maintainability: Maintain declarative pipelines and infrastructure with a lean cross-organization team.
- Extensibility: Extend the platform with domain-specific tooling and libraries.
- Reproducibility: Enable structured tracking of metadata and experiments.
- Traceability: Enable lineage tracking of artifacts and release reports.
- Usability: Allow self-service for onboarding and debugging.
Implementation
Given the highly interdependent nature of the work, we started out by building a small virtual cross-organization team with expertise in machine learning, distributed systems, and infrastructure. We then began the work by establishing a small but critical training workflow and onboarding a few users from one of our core model development teams. After iterating on this initial pilot workflow, we expanded to cover the end-to-end ML model landing workflow.
Infrastructure
We chose open-source Kubeflow Pipelines as our ML orchestration layer since it provides us with a rich set of foundations (UI, metadata tracking, common ML tools) and allows us to extend to domain-specific vertical features (in-house metrics and visualization integration). Standing up a Kubeflow cluster and necessary infrastructure was an easier task thanks to existing expertise in running production Kubernetes clusters on our infrastructure team.
We installed Kubeflow on EKS clusters using Terraform to manage the permissions and resources, which are provided by AWS Managed Services. Experiment metadata is automatically tracked and logged within the Kubeflow UI, which allows for easier experimentation. And we customized the Kubeflow Kubernetes manifests for our enterprise environment to handle user login and group management, so each model development team has a separate namespace in Kubeflow.
Pipelines
At Aurora, pipelines use a set of common utilities, Bazel macros, and launch scripts. For example, below is the structure of a pipeline definition for one of our models.
- BUILD is a file that contains the Bazel targets for the pipeline and the Docker images.
- launch.py contains the command line interface for pushing the Docker images and launching this pipeline with specific parameters.
- pipeline.py contains the pipeline definition and factory function, which looks like a standard Kubeflow pipeline definition but with our specific components.
- pipeline_test.py contains the pipeline-specific unit tests.
- smoke_test.sh is an integration test for the pipeline.
Users can invoke the shell script from their workstation command line interface with a pull request command (a preconfigured command that runs on a code change within a pull request) or as part of a CI/CD process. For example, running this command on a pull request will kick off a model training workflow:
/kubeflow train --model [model name] --training_type [core, deploy, integration]
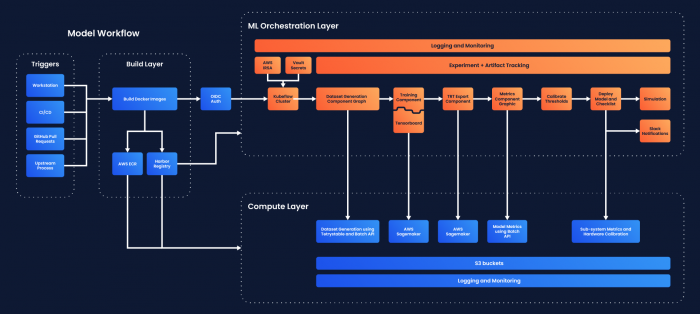
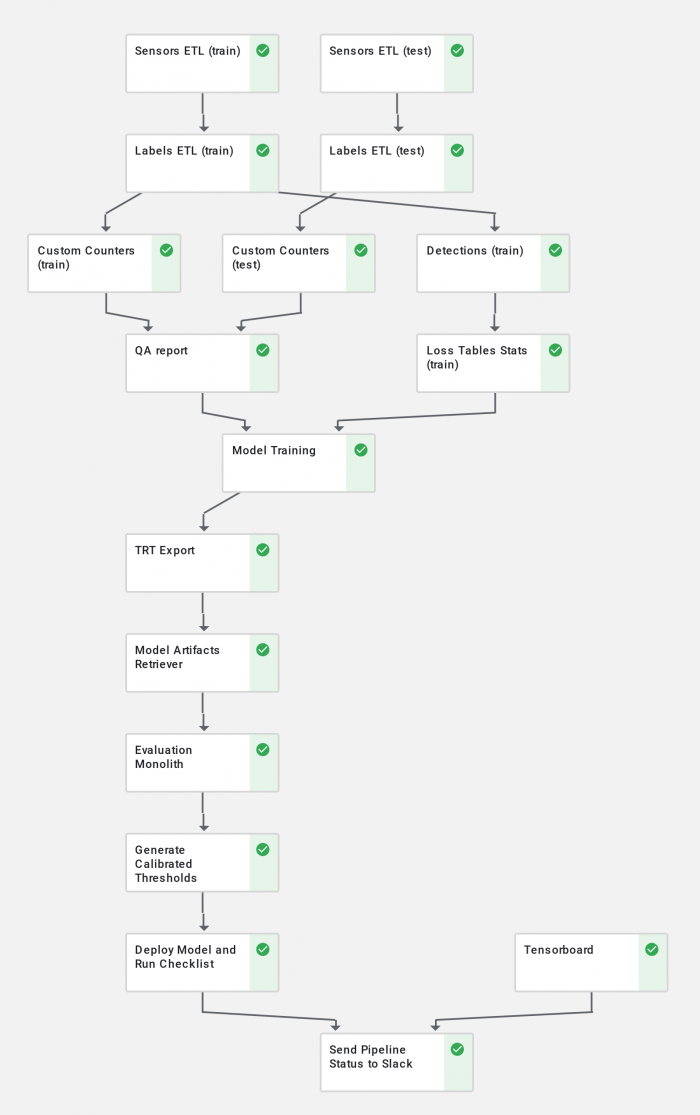
This is an end-to-end depiction of an executed Kubeflow pipeline, covering the entire development workflow including dataset generation, quality reporting, model training, model exporting, model deployment, evaluation, and landing.
To create a pipeline that could be easily inserted into our model development teams’ existing workflows without introducing new processes, we built foundational utilities with common data structures, components, and libraries. Building any sort of integration (internal or external) in the pipeline is time-consuming, so we tried to reuse as many existing integrations as possible between pipelines.
Different teams use different development strategies, but inconsistencies in a code path or configuration could lead to the need to maintain multiple bespoke, and likely brittle workflows that would require precious engineering support time. To avoid this issue, we implemented a feature that would allow our model development teams to launch the new pipelines within their existing workflow. We also built a dashboard to keep track of pipeline usage across different use cases. This dashboard is particularly useful for proactively identifying opportunities for pipeline consolidation or deprecation.
Components
We support a number of common components that are used across different model workflows and teams. In order for our pipelines to cover larger end-to-end workflows, we created Kubeflow components for our internal services like Batch API and our data processing and metrics evaluation frameworks. We’ve also built a number of bespoke components that are specific to a model or workflow. These custom components have unlocked most of our Data Engine automation use cases.
- Sagemaker: Launches distributed model training on Sagemaker. We use a simple wrapper over the open-source Sagemaker component.
- Slack: Sends a notification to a Slack channel or user, mainly used as an exit handler for every pipeline.
- GitHub: Integrates with common functions such as ‘create PR,’ and ‘comment on PR.’ This allows us to connect parts of the workflow that are not yet integrated into Kubeflow.
- Batch API: Launches distributed compute jobs such as dataset generation and metrics evaluation on our internal batch platform.
- Tensorboard: Launches a Tensorboard instance for a specific training job on Kubeflow.
At Aurora, there are two use case-specific ways of creating new components that come with pre-baked Aurora libraries—as a Python function with a helper Python wrapper and as a binary with a helper Bazel macro. All our components and pipelines are created with a factory method to allow overriding of any compile-time parameters (e.g., Docker images) and are compiled at the time of execution. This ensures that the components and pipelines being built are always up-to-date with the rest of the dependencies and code in the monorepo.
Adoption
Driving adoption for a new way to manage and run workflows is always tricky—you must convince your users that changing how they develop won’t negatively impact their development velocity and at the same time demonstrate that there are real benefits to using the new approach.
To align with our users’ needs and truly add value, we worked closely with Aurora’s model development teams during each phase of the ML orchestration layer’s development, ensuring code maintainability and encouraging workflow consolidation, where possible. We started building pipelines incrementally, focusing on a small set of stages and a few beta users. Once the first pipeline was operational and the value-add was clear to the engineers’ work, the project gained momentum and it became easier to convince and onboard other model teams.
We wrote several code labs, conducted internal deep dives, and held office hours to increase awareness of the new tools. We also designed a Kubeflow-specific pull request command on GitHub and an integration with Buildkite for scheduling CI/CD builds, which made it very easy for other developers to run integration tests and experiment quickly without learning team-specific workflows. As a result, we’ve caught a number of bugs and regressions in dataset quality and model performance that would otherwise have been very difficult and time-consuming to find and debug.
Today, the majority of Aurora’s autonomy model developers use our centralized ML orchestration system for their development and production workflows. Our users typically launch at least one pipeline a day in one of the following ways.
- Command Line Interface (CLI): This is the standard way to launch a pipeline from a workstation. It is mainly used by developers for quick experimentation and trying out changes before a pull request for a code change can be created.
- Pull Request (PR) Commands: This has quickly become one of the most popular ways to launch a pipeline for running integration tests on pull requests for validation and verification, and also for launching core experimentation and production deployments on the cloud.
- Continuous Integration (CI): These are automated tests and runs to monitor the health of workflows.
- Continuous Deployment (CD): These are automated runs of end-to-end deployment workflows to create datasets and train and deploy models on newly labeled data.
As a result of our team’s hard work, we have drastically cut down the time spent on the production and deployment of models on new data. We have reduced the manual effort required during experimentation and sped up model development workflows, saving time during dataset generation, training, and evaluation, and allowing our engineers to iterate on ideas much more quickly.
Interested in building the future of the self-driving industry? We’re hiring! Apply here.
Ankit Aggarwal and Vinay Anantharaman
Ankit is on the Datasets and Pipelines, Autonomy team, and Vinay is part of the Machine Learning Operations and Infrastructure team.
Don’t forget to share this post:

.png)
.png)