
.png)
Implementing Data Contracts for Entities by: Chad Sanderson and Adrian Kreuziger Note from Chad : 👋 Hi folks, My name is Chad Sanderson, and I write about data products, data contracts, data modeling, and the future of data engineering and data architecture
Implementing Data Contracts for Entities
by: Chad Sanderson and Adrian Kreuziger
Note from Chad: 👋 Hi folks, My name is Chad Sanderson, and I write about data products, data contracts, data modeling, and the future of data engineering and data architecture. Today’s article is a special one. Over the past few weeks, the discourse around data contracts has exploded.
Some of this discourse has been meaningful and thoughtful, and some has been unhelpful and misses the point. This is partially because the loudest voices on the topic (me included) have yet to provide any sort of comprehensive, technical guide around the way contracts should be created, enforced, and fulfilled.
That technical guide is what today’s post is all about: A comprehensive look into data contracts as a technology using open source components. It’s authored by my friend and co-worker, Adrian Kreuziger, a Principal Engineer at Convoy who has been a driving force in bringing contracts to life. With that, I will turn things over to Adrian. Please remember to like the post and share! I’ll owe you one.
-Chad
Forward
Data Contracts are API-based agreements between Software Engineers who own services and Data Consumers that understand how the business works in order to generate well-modeled, high-quality, trusted, data. If you are hearing the term data contracts for the first time or are not sure why data contracts are useful, go read the Rise of Data Contracts for a detailed explanation before diving into this implementation guide. This article is part one of a three-part series on the technical implementation of data contracts.
Part I: Entities: We reviewa CDC-based implementation of Entity-based Data Contracts, covering contract definition, schema enforcement, and fulfillment.
Part II: Application Events: A follow-up to the Entity Data Contracts article covering the implementation of application-level events, including the use of the Transactional Outbox pattern. (Coming next week)
Part III: Semantics: Data Contracts cover both schemas and semantics. While the previous two articles address schema enforcement, this article reviews an implementation for the enforcement of semantic contracts and the need for good monitoring (Coming once we’re all back from vacation).
With that out of the way, let’s begin by exploring the foundations of entity contract implementation as an extension of Change Data Capture.
Contracts, Services, and Change Data Capture (CDC)
While most people probably understand why data contracts are valuable in theory, what do they mean specifically in the context of a service? How does a service fulfill a contract? To start, let’s review some helpful terminology.
Data Contracts allow a service to define the entities and application-level events they own, along with their schema and semantics.
Entity events refer to a change in the state of a semantic entity (AKA nouns). In the freight world, this might include a shipper, shipment, auction, or RFP. Changes occur when the properties of each entity are updated, such as whether or not a shipment is on time, its pickup and dropoff location, and its current status.
Application events refer to immutable “real world” events and their properties published from application code that make up snapshot of the world captured when the event occurred (AKA verbs). As an example, while ’ canceled’ might be a value of the shipment_status property, the shipment_cancelled event would be emitted from a location in the code where the event is recorded.
So are Data Contracts just a fancy term for APIs? The short answer is yes. The long answer is that the term Data Contracts is being used to introduce a concept: There must be a formal agreement between data producers and consumers where one did not really exist before.
Software developers are used to thinking about how systems interact with other systems (APIs), but rarely put the same level of thought into the data their systems produce. Often, this is because application and data teams are separated by ELT/ETL infrastructure, and developers have little visibility into how the data is being consumed. To data producers, the data platform is an opaque black box. To data consumers, data producers are unreachable and too upstream to prioritize their use case. Evangelizing the term data contracts is a way to raise awareness of this issue even though the implementation is roughly aligned with what developers have already been doing using APIs.
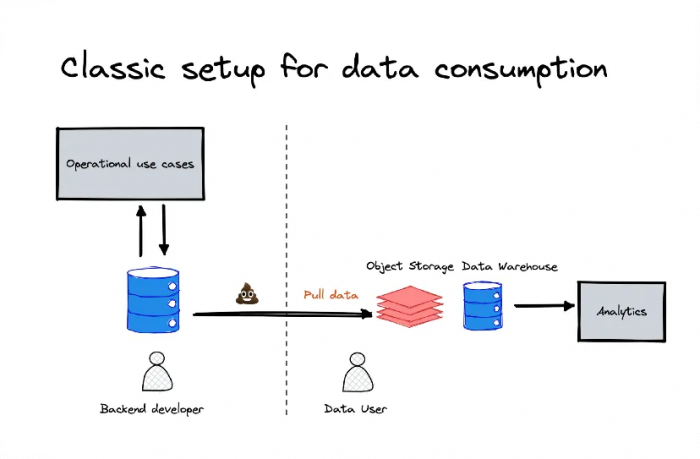
Change Data Capture (CDC)
Data contracts apply to both entities & application-level events, and while conceptually contracts work the same way for both, the implementation differs. Implementation of entity contracts is powered by a process called Change Data Capture which has become a popular method of syncing data from production systems to the data warehouse. CDC works by capturing all row-level changes in a database. This gives it several important properties that make it the best choice for powering entity contracts:
- It runs at the data store level, not the application level, meaning you’re guaranteed to get all updates to an entity.
- If implemented correctly, you’re guaranteed at least one delivery, so you won’t ever lose an update to an entity. CDC would provide a complete audit trail of all changes over time.
While this is extremely useful as a foundational technology, using CDC events directly is a bad engineering practice.Becausethere’s no layer of abstraction between the service’s data model and consumers, developers aren’t free to make necessary breaking changes without consulting downstream consumers first. It breaks encapsulation by exposing the internals of the service to consumers, encouraging them to take dependencies on implementation details that could (and should be able to) change in the future. Unfortunately, direct applications of CDC are extremely common in the industry (I even wrote an article about how to do it a few years ago). In most implementations of traditional CDC, there is no formal contract. This results in downstream consumers suffering the most.
While still powered by CDC under the hood, the below implementation addresses these problems by adding abstractions and enforcing data contracts for entities.
Using CDC Events directly is a bad engineering practice
Requirements
Data Contracts are first and foremost a cultural change toward data-centric collaboration. In order to most effectively facilitate that cultural change, the implementation of contracts from a technical point of view must fulfill several basic requirements:
1. Data contracts must be enforced at the producer level. If there’s nothing enforcing a contract on the producer side, you don’t have a contract. That’s a handshake agreement at best, and as the old saying goes: “A Verbal Contract Isn’t Worth the Paper It’s Written On”.
There are other, more practical reasons for enforcing contracts at the producer level.The data flowing out of your services can (and should) be used beyond the data warehouse. For example – you might want to hook a machine learning feature store up to this live data to compute real-time features for your ML models, or other engineers could depend on this data for additional service-driven use cases.
2. Data contracts are public. The implementation needs to support evolving contracts over time without breaking downstream consumers, which necessitates versioning and strong change management.
3. Data contracts cover schemas. At the most basic level, contracts cover the schema of entities and events, while preventing backward incompatible changes like dropping a required field.
4. Data contracts cover semantics.In API design, altering the API’s behavior is considered a breaking change even if the API signature remains the same. Similarly, changing the underlying meaning of the data being produced should break the data contract. As an example – if you have an entity with length and width as numeric fields, switching the values from being stored in inches to centimeters is a breaking change. In practice, this means contracts must contain additional metadata beyond the schema, including descriptions, value constraints, and so on.
Detecting and preventing semantic changes deserves an entire post of its own (part 3 of this series). For this article, we’ll only be focusing on enforcing the schema-centric aspect of contracts.
5. Data contracts should not hinder iteration speed for developers. Defining and implementing data contracts should be handled with tools already familiar to backend developers, and enforcement of contracts must be automated as part of the existing CI/CD pipeline. The implementation of data contracts reduces the accumulation of tech debt and tribal knowledge at a company, having an overall net positive effect on iteration speed.
6. Data contracts should not hinder iteration speed for data scientists. By definition, many science & analytics workflows are experimental and iterative – you often don’t know exactly what data you need until you have a chance to play around with what’s available. Access to raw (non-contract) production data should be available in a limited “sandbox” capacity to allow for exploration and prototyping. However, you should avoid pushing prototypes into production directly. Once again, the implementation of data contracts reduces the accumulation of tech debt and tribal knowledge at a company, having an overall net positive effect on iteration speed.
Implementation: Define, Enforce, Fulfill, and Monitor
The implementation of data contracts falls into four phases: defining data contracts, enforcing those contracts, fulfilling the contracts once your code is deployed, and monitoring for semantic changes (that, unfortunately, can’t always be caught prior to deployment). The diagram below lays out the full architecture of a data contract implementation, from definition to deployment. We’ll break down each component in more detail in subsequent sections.

Data Contract Definition
Data Contracts must be code & version controlled, preserving history and context for change management, allowing them to be validated and enforced as part of your CI/CD workflow.
Defining contracts for entities is done using well-established open source projects for serializing and deserializing structured data. Two common projects are Google’s Protocol Buffers (protobuf), and Apache Avro. Both provide an IDL (Interface Definition Language) allowing the schema of events (the contract) to be written in a language-agnostic format, which is then used to generate the code needed to serialize an event’s payload before publishing to Kafka. As an example, here’s a simple Order contract defined using protobuf:
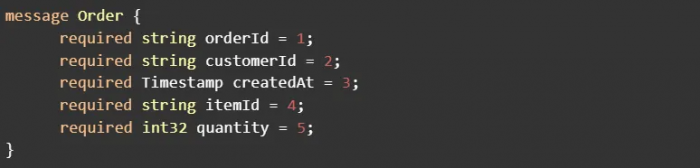
Both projects provide options for adding metadata to contract definitions that can be used to annotate the contract with ownership and description metadata or specify value constraints for fields (which will be covered more in-depth in part 3 of this series). Protobuf allows for custom options, and when defining a schema the Avro specification states “Attributes not defined in this document are permitted as metadata, but must not affect the format of serialized data.”
Data Contract Enforcement
A contract by definition requires enforcement. While agreed-upon semantics are more challenging to catch pre-deployment, a mechanism to prevent schema-breaking changes MUST exist. By making contract definition part of a service’s code, we’re able to validate and enforce contracts in our CI/CD pipeline as part of the normal deployment process. There are two steps to contract enforcement – making sure ensuring a service’s code will correctly implement the defined contracts, and ensuring any changes to a contract won’t break existing consumers.
Integration Tests
We use fully automated integration tests to verify the service correctly implemented the data contracts. While you should always maintain entity-level integration tests that check for correctness as the service’s APIs are called, we can automate schema correctness checks such that there’s no change required by a developer when adding or modifying a contract. This process assumes you have some method of producing a test database instance as a Docker container with the same schema as your production database.
The process relies on Docker Compose (or your container orchestration system of choice) to spin up a test instance of your database, your CDC pipeline, Kafka and the Schema Registry, and the stream processing jobs for your entity contracts (more details on these jobs in the below Data Contract Fulfillment section). Running the stream processing job for an entity verifies that it’s implemented correctly. It also provides the chance to compare the job’s output schema that gets pushed to the test schema registry, against the entity contract schema you defined earlier. Because the process is the same for all entity contracts, the test will run automatically for each, eliminating the need for any manual updates to these tests when adding or modifying a contract moving forward.

Note: depending on your tech stack you might choose to simplify the above implementation. For example – if you’re using a JDBC compatible database and kSQL you could skip spinning up Kafka + your CDC pipeline in Docker, and just run your kSQL directly against the test database using their JDBC Source Connector plugin
Schema Compatibility
For the second step, we use the Confluent (Kafka) Schema Registry. Once we’ve verified the service code will correctly fulfill the defined contracts, we take the schemas of the entity contracts and use the production schema registry to check for backward incompatible changes.
Because this is a producer-centric approach to data contracts (the producer is updated first), the schema registry compatibility mode needs to be set to `FORWARD`. This might seem counterintuitive, but it means the “data produced with a new schema can be read by consumers using the last schema, even though they may not be able to use the full capabilities of the new schema”, which is just a fancy way of saying you can add new fields, and delete optional fields. You can read more about compatibility modes and schema evolution here.

Finally, once all enforcement checks pass, we publish any new contracts, or new versions of an existing contract to the Schema Registry prior to deploying the code.
Data Contract Fulfillment
As mentioned above, using raw CDC events directly is bad engineering practice. To introduce a layer of abstraction between the service’s data model and the final entity contract, we use stream processing to morph raw CDC events from one or more of the service’s tables to match the entity contract. Services define stream processing jobs that listen to the service’s own raw CDC events and transform those events into a single entity update event that fulfills the contract.
Using a stream processing framework with a SQL dialect (kSQL, Apache Flink, Materialize) developers can treat their CDC events like the tables in their service’s database, and write simple SQL statements whose output schema defines the entity data contract. Common examples of these jobs are hiding internal details by SELECTing only a subset of columns from a table or JOINing the streams of multiple normalized production database tables to produce a denormalized view of an entity.
Using the above Order entity example – let’s say you have an orders table in your production Postgres database with the following schema:
You don’t want to expose the customer’s contact phone number as part of your public data contract because it’s PII, so your kSQL would look like this, with a schema that matches your previously defined Orders contract:
I previously wrote an article diving into how CDC with the Debezium project works, but as a quick recap: the Debezium project is a Kafka Connect connector that listens to the transaction log of a database and produces an event for each row-level change. The deployed stream processing job consumes the CDC events and emits a new entity update event to the entity’s public contract topic based on the processing job’s SQL statement. To prevent production consumers from taking a direct dependency on the CDC events, we section our Kafka cluster into “public” contract topics which are available to all potential consumers at the company, and “internal” CDC topics which are generally not accessible by other consumers. What topics are public or internal are controlled using Kafka read ACLs.
The end result of the fulfillment process is low latency and trustworthy data ready for a variety of consumers, including the data warehouse. This opens up the data to new applications of infra & use cases like search indices, caching, service-to-service communication, stream processing, and so on.
Data Contract Monitoring
Like all software development, even with extensive testing bugs still slip through the cracks into production. The most difficult bugs to catch are often subtle changes in behavior that don’t immediately trigger alarms. Data is no different. There are simply some aspects of semantic enforcement that cannot be reliably managed prior to deployment. You enforce what you can by explicitly implementing value constraints or using statistical analysis during testing and staging environments, but at the end of the day, you need good monitoring to alert you to changes in the semantics of your data. Part 3 of this series will focus on exactly this – the enforcement and monitoring of data contract semantics.
Final Thoughts
While the above implementation adds technical complexity to the process of syncing data from your production systems to the data warehouse, it’s important to understand that stable, trustworthy, agreed-upon data will ultimately reduce the complexity of your Lake/Data Warehouse in a very material way. It’s a tradeoff, but in my experience managing the above technical complexity is far easier than managing the organizational and business complexity that evolves over time in a company’s data environment, especially as the company grows.
-Adriank
Final, Final Thoughts (From Chad): If you made it this far, thanks for reading. While we covered the technical implementation of contracts here, it is still only a small part of what’s needed to make the collaboration between data producers and data consumers work.
Data Contracts are indeed a cultural change, but, like any other area of innovation that impacted culture from CI/CD to Electric Vehicles, simple-to-use technology makes it easier for people to do the right thing who may have been incentivized otherwise. In our case, contracts are the surface through which conversations around data can begin to emerge. Those conversations bring awareness to how upstream data is being used downstream, its importance, and its impact on the business. By providing an ‘on-ramp’ to contracts that begin with the lowest possible lift for engineers and culminating in fully decoupled events built for the purpose of analytics, there is a built-in maturity curve to data contracts that becomes more meaningful the farther right you go.
With that in mind, if you have questions about data contracts then my metaphorical door is always open. We would deeply appreciate it if you liked and shared this article (for the algorithm!) and please stay in touch.
-Chad
Subscribe to Chad’s newsletter or follow him on LinkedIn to stay up to data with data contracts.
.png)


.png)