
This blog is written by Kyle Gallatin , a software engineer on the machine learning platform team at Etsy
This blog is written by Kyle Gallatin, a software engineer on the machine learning platform team at Etsy.
💡 Learning about production ML systems is hard, and getting hands-on experience with them can be even harder. In this post Kyle Gallatin blog breaks down some common components of production ML systems and demonstrates how you can implement simplified versions of them using just Python code.
A foundational base to learn—and build on—the basics of MLOps componentsI recently gave a talk on Machine Learning in Production for NYC Data Science Academy from which I’ve adapted this post. The purpose of this article is to demonstrate the basic functionality of some components of a production ML system using only Python code. For folks interested, I’ll also be teaching a Machine Learning in Production class in 2022–23!
Disclaimer: Nothing in this article represents the setup for an actual production system, but is meant instead to be an educational tool representing some of the lightweight capabilities of some of these tools to familiarize folks who haven’t had the chance to work with these systems.
That being said, each code snippet below is meant to demonstrate some of the things you might see in a production ML system that implements MLOps — using only Python! Cool right? To get started, make sure you have the following libraries installed:
pandas
sklearn
pytestBelow is some synthetic user data we’ll use for the purposes of this tutorial. It contains two input features and a target. Not really indicative of a real scenario, but good for demonstration purposes:
import pandas as pd
url = "https://raw.githubusercontent.com/kylegallatin/components-of-
an-ml-system/main/data/user_data.csv"
user_data = pd.read_csv(url, index_col=0)
user_data.head()
Now let’s get started…
Feature Store
Feature stores (and feature systems) intend to make it easy to manage, productize, and define features for machine learning systems. They can typically be used for both model training and for low-latency serving. Some technologies to take a look at: Tecton, Feast.
The solution below allows us to convert our user data into a dictionary where user_id is the key – so we can retrieve features for users we want to make predictions for quickly on the fly. It also doesn’t prevent us from reading all of the data during the training process.
We can initialize this class with our data, and then define new features as functions! The function will automatically be applied to our data and create the new features:
feature_store = SuperSimpleFeatureStore(user_data)
def new_feature(feature_dict: Dict) -> Dict:
return feature_dict["feature_1"] ** 2
feature_store.register_feature("feature_3", new_feature)
feature_store.get_user_feature("a27b09ee-0cf8-11ed-899e-b29c4abd48f4")
ML Metadata Store (Experiment tracking) and Model Registry
ML metadata (experiment tracking) is essentially your lab notebook for data science projects. The idea is you capture all metadata and information about experiment runs to make things reproducible. On top of that is a model registry, which would be a more central place to manage and version models. Some tools to look at: MLFlow, Weights and Biases, Comet, Sagemaker.
In this case — our design is simpler. We’ll just capture all the information about our experiments in a CSV file that we use to track results.
Now that we have our helper functions, we can do different training runs and records the results:
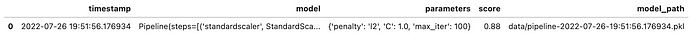
Everytime we run the code above, we’ll append another row to our “ML Metadata Store”
Automated Training Pipeline
Once model code, data, and parameters are optimized, code can be abstracted to a source-controlled repo (git) and the training code can be scheduled and automated. In cases like e-commerce, there is already new data coming in and models frequently need to be retrained. You want to automate the process of training and deploying models whose parameters have been fairly set. Some tools to look at: Airflow, Kubeflow.
In perhaps the biggest oversimplification thus far, I’ve compiled the code thus and put it in its own Python script — then added an infinite loop to continuously train the model with a 1-minute sleep in between each run. That way, we can run the script in the background to continuously train new models (with a 60-second sleep in between runs).
To run this script in the background, use:
python3 main.py &Continuous Integration
Continuous integration is the act of actively committing changes to a central repository, and also covers automated tests and builds. Most of these actions are triggered by git commits and pushes to remote repositories like Github. In this case, I’ve added a simple test that can be run using pytest. While there is not automation yet, this is a good starting point for setting up testing within a ML repo. Tools to look at: Jenkins, Cloud Build, Buildkite.
pytest
ACTION: practice CI on your own by adding the pytest command as a git pre-commit hook (ie will run whenever you try to commit code).
Continuous Delivery/Deployment & Model Server
Continuous delivery is the practice of reliability releasing small iterative changes to software to ensure it can be reliably shipped. Continuous deployment is just consistently deploying. In the case of ML this would be part of the automated process — where a model training pipeline automatically ships a newly trained model to a model server. Tools to look at: Jenkins, Cloud Build, Buildkite, Argo CD.
A model server is typically an HTTP server that accepts input features and returns predictions. Tools to look at: Tensorflow Serving, Seldon Core.In this case, instead of doing “CD” we’re just updating and loading the latest trained model at every prediction (remember its updating in the background). Then, we use a predict function instead of a model server to fetch features for a given user ID and make a prediction.
array([0.])In a real scenario, we would never load the model again for every prediction, but this code ensures that we’re using the latest model no matter what. To improve upon this solution, try adding code to only read a new model in if there are changes to our Model Store!
Performance Monitoring
Monitoring and observability of production systems is absolutely one of the most critical components of one. Real systems also have alerting to notify engineers of production issues. In this case, we’ll create a simple monitor that records the latency of predictions and reports on the mean. Some tools to look into: Prometheus, Grafana.
This code adds a very simple monitoring class that tracks and records the amount of time to make a prediction.
If we want to see average prediction time as we continue to make predictions, we can use the monitor to do so!
monitor.mean()
Conclusion
Production systems are difficult, and it’s even more difficult to get hands-on experience with them without working in industry for quite some time. While none of the code or examples above are “production-ready”, they should give you a foundational base to learn the basics of these components and then build on them.
Out in the wild, you’ll likely see many different combinations and implementations of the components represented here — including others I haven’t included! If there are additional concepts you’d like to see in this article, please let me know! See the git repo for this project here.
I’ll be teaching a course in production Machine Learning this fall, please reach out on LinkedIn or Twitter if interested!



.png)